End-to-End Captcha Recognition With Few Labels: From SimGAN to Transfer Learning

文章目录
基本信息
摘要:验证码是保护网站免受恶意攻击的一种常见机制,其中基于文本的验证码使用最为广泛。虽然机器学习技术已对其安全造成威胁,但现有的大多数攻击都耗时耗力,需要预处理图片或者大量人工标注数据。在这篇文章中,我们试图通过利用SimGAN使模拟验证码与真实验证码更加相似,从而训练出一个端到端的模型来识别真实验证码。然而,我们的实验结果不能表明SimGAN对准确性有任何积极影响。相反,转移学习中的微调过程才是关键因素,它仅凭一些有标签的真实图像就能大大提高模型性能。
关键词:验证码识别,生成对抗网络,迁移学习
Abstract: CAPTCHA is a common mechanism to protect websites from malicious computer bots, among which text-based captcha is the most widely used. While machine learning techniques have posed a threat to them, most of the existing attacks either require image preprocessing or a large number of manually labeled data, which is time-consuming. In this article, we try to train an end-to-end model to recognize real CAPTCHAs with just synthetic samples, by utilizing SimGAN to make simulated CAPTCHAs more similar to the real ones. However, our experiment results cannot show SimGAN have any positive impact on the accuracy. Instead, transfer learning, especially the fine-tuning process is the key factor which can improve the performance of the model significantly by just a few labeled real images.
Keywords: Captcha Attack; Transfer Learning; Generative Adversarial Network
引言
验证码的全称是全自动区分计算机和人类的图灵测试(Completely Automated Public Turing test to tell Computers and Human Apart,CAPTCHA),在2003年由路易斯·冯·安(Luis von Ahn)等提出,在互联网活动中起着重要作用,诸如在网站注册、登录和密码找回等环节中,验证码能有效抵御自动化攻击。 尽管验证码的新形态不断出现,原始的字符验证码仍然在被广泛应用,攻击方和防守方的不断对抗也在不断进行,字符形态的扭曲,连人类都不一定能准确识别。但随着深度学习的流行,识别方开始占据上风,利用 CNN 等神经网络训练的模型能达到很高的识别率。 然而基于监督学习的神经网络依赖于海量的标签数据,需要前期人工标注打码,成本高昂,而且模型的迁移性较差,一旦验证码生成方式改变,就需重新打码并训练模型。如何利用无标注的数据进行分类,自监督学习、半监督学习、伪标签,数据增强等手 本文综合利用人工合成的验证码和无标注的真实验证码来训练神经网络,对某网站的验证码样本进行识别,先是尝试训练 SimGAN[2] 让合成验证码学习到真实验证码的分布,但效果不佳。最终在发表于2020年的论文 Simple and Easy: Transfer Learning-Based Attacks to Text CAPTCHA[1] 中得到结论,使用 GAN 等方式试图让合成验证码更像真实验证码对准确性的提升没有较大影响,用少量标注过的真实验证码 finetune 预训练的神经网络才能大大提高准确率。
验证码安全概述
验证码的种类与发展
按照信息类型的不同,现有的验证码可分为两类:一类是基于视觉的验证码,包括文本类验证码和图像类验证码;另一类是基于听觉的语音类验证码,基于视觉的验证码通过识别验证码中对象所属的类别实现验证,基于语音的验证码则匹配语音中包含的验证信息实现验证。 早期的验证码,都是基于人可以一目了然看懂文字,而不能轻易让程序实现分类而出发。然而,随着计算机发展的愈发智能和类人化,我们能否还能区分人与计算机?这是验证码的根本问题。Alpha Go 击败人类顶尖棋手让我们看到了 AI 在解决特定任务上的出色能力,为了不让验证码被自动化轻易程序识别,验证码的外在形态和任务逻辑早已变得非常复杂,长期对抗下来,就形成了机器人和用户都看不懂的尴尬局面,用户的体验成了这场战争中的牺牲品。所以业界也在尝试应用基于行为的新型验证码,将更多更强的风控 SDK 嵌入前端,从而依据滑动轨迹,浏览器特性,前端代码保护等能力,将对抗迁移到用户层迁移到了代码层,不再单纯依赖用户是否正确完成任务来进行判定,验证码对抗进入新的时代,不过这不是本文讨论的重点。
文本型验证码的对抗
由于文本类验证码具有交互方式简单、密码空间大且场景适应性强等特点,在实际应用中被广泛接受.调查发现,在Alexa发布的全球综合排名前50的网站中,80%的网站在登陆、注册、输错密码或者密码找回环节中使用验证码来抵御自动化攻击,其中包含微软、百度等在内的 60% 的网站均在使用文本类验证码。[5]
因此,深入研究文本类验证码的安全性对于改进传统验证码生成方法具有重要意义,本文研究对象及下文所提到的验证码皆为文本类验证码。
最初的文本验证码仅仅只是手写字体样本标注的识别问题,比如下图中的验证码,曾经有一部分是取自历史书籍的截图,从而借网友之力标注文本的图书馆转为电子档。
这种验证码,易于切割文字清晰,很快就能被破解。目前,文本验证码的安全性主要靠背景干扰信息和字符粘连两个因素来进行保证,这两个安全特征都在不同程度上增加了识别难度和分割难度。除此之外还有中文和动态 GIF 验证码来增加分类数量或提高定位难度,但可能影响用户体验,所以常见的码仍以字符重叠、扭曲、倾斜和偏移为主。
传统方法识别文本型验证码的步骤如下:首先,通过二值化、空间滤波、变换等图像处理技术去除验证码中的干扰信息。其次,使用投影、类聚或目标检测等方法确定字符在图像中的位置并进行分割。最后,利用SVM、KNN等机器学习方法提取字符特征并进行分类识别。[6]
基于神经网络的深度学习方法则无需繁琐的图像预处理步骤,强大的神经网络可以进行端到端的学习预测,但模型的解释性较差,且需要大量标注样本。
基于SimGAN的生成对抗网络
生成对抗网络
生成对抗网络(Generative Adversarial Networks,GAN)的诞生受到博弈论的启发,通过对抗训练的方式来使得生成网络产生的样本服从真实数据分布,其中博弈双方分别是判别网络(Discriminative Network)和生成网络(Generative Network),判别网络的目标是尽量准确地判断一个样本是来自于真实数据还是由生成网络产生,生成模型的目标是尽量生成判别网络无法区分来源的样本。这两个目标相反的网络不断地进行交替训练。当最后收敛时,如果判别网络再也无法判断出一个样本的来源,那么也就等价于生成网络可以生成符合真实数据分布的样本。
判别网络𝐷(𝒙; 𝜙)的目标是区分出一个样本𝒙是来自于真实分布 𝑝𝑟(𝒙) 还是来自于生成模型 𝑝𝜃(𝒙),因此判别网络实际上是一个二分类的分类器.用标签𝑦 = 1来表示样本来自真实分布,𝑦 = 0表示样本来自生成模型,判别网络𝐷(𝒙; 𝜙)的输出为𝒙属于真实数据分布的概率,即𝑝(𝑦 = 1|𝒙) = 𝐷(𝒙; 𝜙), 则样本来自生成模型的概率为𝑝(𝑦 = 0|𝒙) = 1 − 𝐷(𝒙; 𝜙)
给定一个样本(𝒙,𝑦),𝑦 = {1,0}表示其来自于𝑝𝑟(𝒙)还是𝑝𝜃(𝒙),判别网络的目标函数为最小化交叉熵,即
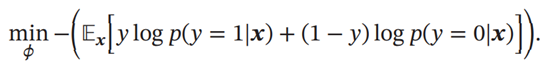
生成网络的目标刚好和判别网络相反,即让判别网络将自己生成的样本判别为真实样本
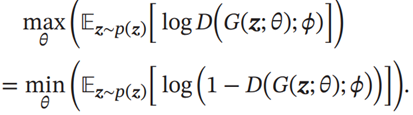
上面的这两个目标函数是等价的.但是在实际训练时,一般使用前者,因为其梯度性质更好。
SimGAN论文解读
SimGAN 是苹果公司的首篇 AI 论文,获得了2017年的 CVPR 最佳论文奖,论文全名是 Learning from Simulated and Unsupervised Images through Adversarial Training,即使用「模拟+无监督」的学习方法,通过没有标签的真实图片来提高仿真器生成图片的真实性,同时还保持原有合成图片的标签,最终得到一批带标签的,真实的图像数据集。
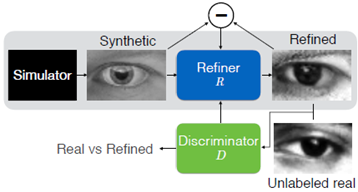
论文中构建了如上图所示的 GAN 网络,简称 SimGAN 。经典的GAN是先从标准正态分布开始逐步接近训练数据的分布,而在 SimGAN 中则是模拟器生成一批带标签的合成图片,然后将合成图片送入到修正器 Refiner 中,Refiner 学习真实图像的一些特征,对合成图像进行修正,得到修正后的图像与未标注的真实图像一同送入分辨器中。如果分辨器将修正后的图像判别为真实,则固定 Refiner 的参数不变,根据损失函数,反向传播来优化分辨器的参数;如果判别为假,则固定分辨器的参数,对 Refiner 的参数进行优化。
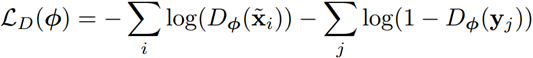
上述公式表示 Discriminator 用来更新参数的损失,其中 $\tilde{x} _i$ 表示合成图片, $y_j$ 表示真实图片,Dφ是输入为合成图片的概率,1-Dφ是输入为真实图片的概率,其实就是二分类交叉熵损失函数。
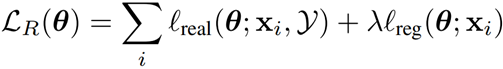
上述公式表示 Refiner 需要同时最小化两个损失来更新参数,其中 $l_{real}$ 是合成图片与真实图片y之间的差异,第二部分$l_{reg}$是修改过后的图像与原合成图像的差异。
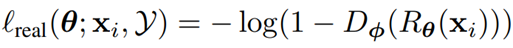
Refiner 要最小化$l_{real}$,即尽可能让 Discriminato r将合成图像误分类为真实图像,最小化$l_reg$是为了惩罚修正后的图像和原始图像之间的巨大差别,避免 Refiner 在修正合成图片的时候用力过猛修改了图像的内容,这也是本文相比于经典 GAN 的一个创新点。
还有一个创新点作者定义的 Discriminator 是局部分辨器而非全局分辨器。将输入分辨器的图像进行分割,将其分成 w*h 的小块,逐块的送入分辨器中,这样限制了接受域的大小,避免了 Refiner 过分强调对某一部分的修正来欺骗分辨器,而且这样分块之后一幅图像对应着 w*h 个样本,丰富了样本的数量。
在无标注真实验证码上的实验
验证码的选取与合成
真实验证码来自 https://passport.bilibili.com/web/captcha/img,每次访问该地址都会随机更新图片且没有频率限制。观察发现该验证码的长度为5,所用字符集为大写字母及数字,颜色均为黑白,没有背景噪音且扰动规律较明显,即字符统一向左或向右倾斜一定角度,略有扭曲,且有一长一短两条线划过字符。
为生成与之相似的验证码,使用了 wheezy.captcha 以合成带有干扰线和扭曲的验证码,共计生成十万余张,真实验证码与最终生成验证码对比如下:

网络的构建与训练
本文构建了三个不同的神经网络,即用于从图片识别验证码文本的 Recognizer,判断验证码是否为合成的 Discriminator 和对合成验证码进行修改的Refiner。
Recognizer即用于图像分类的神经网络,我们期望得到的分类结果是验证码字符串,但网络的输出只有数字,因此手动实现了 one hot 编码,网络最后一层输出的大小即为 串长*字符集长度,将其进行一些 reshape 操作即可解码为字符串。在具体网络模型的选择上,最开始仅选用了三层的 CNN 网络,虽然训练较快,20个 epoch 后就能达到90%左右的准确率,但后续实验表明其泛化能力差,在真实验证码上的准确率不理想,后来受论文的启发替换为 ResNet101,训练了不到10个 epoch 就达到了接近99%的准确率。
Discriminator 也是 CNN 网络,是一个二分类器,区分一个验证码是我们合成的还是真实的样本集。
Refiner 是一个 ResNet,输入尺寸与输出尺寸相同,它在像素维度上去修改我们生成的图片,而不是整体的修改图片内容,这样才可以保留整体图片的结构和标注。
GAN的训练最为关键也最为困难,官方没有公开自己的训练代码,仅有如下算法描述,大致框架与经典的GAN相同。

上图中 Refiner 和 Discriminator 都是选用了 SGD 作为优化算法,而参考了一些网上复现的代码,Refiner 都改用了 Adam,Kg和Kd的选取也需要大量微调,除此之外论文中还使用了一些 trick,比如设置了一个缓存区来存储分辨过的修正后图像,每次向分辨器送入一批次图像时总是从缓存中选取一部分共同参与训练,这样做的好处就是可以避免修正器重新引入了被分辨器遗忘的伪迹,并且避免训练发散。
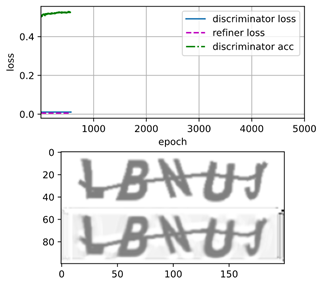
交替训练了500个step后,用Refiner修改后的图片只是变得模糊,似乎并没有更接近真实图片。
效果验证
由于没有时间手动标注真实验证码,所以本文不会计算准确率,而是随机挑选样本中的单张真实验证码图片进行预测,反复几次后既能直观地估计其效果。
预测真实验证码使用了三种方法:直接使用合成验证码训练出的Recognizer对真实图片进行预测;使用Refiner修改后的图片训练Recognizer对真实图片进行预测;用Refiner修改输入的真实图片再让Recognizer进行预测
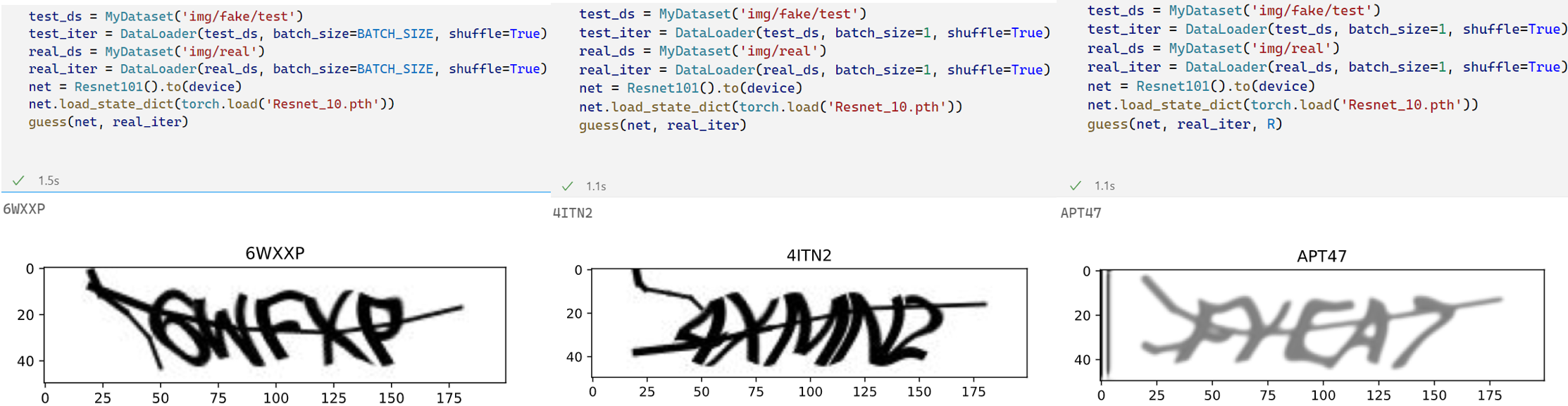
从结果看使用GAN训练的Refiner对提升识别准确率并没有帮助,Recognizer模型本身的选取反而有较大影响,开始仅使用了三层CNN网络,根本无法用于识别真实验证码,换用ResNet101后,如上左图所示,仅在合成验证码上训练过却偶然能识别正确4个字符。而另两张图表明引入Refiner后并没有可感的提升。这里能识别出部分字符应该主要是靠ResNet101的强大学习能力和手工合成验证码的一定相似度,GAN并没有发挥作用。
基于迁移学习的改进方法
迁移学习的基本概念
上述实验用合成图片去训练模型,并试图让其在真实图片上达到较高准确率,实际上有违深度学习的通常假设,即训练数据与测试数据在相同的特征空间且拥有相似的分布。但收集标注样本的成本太高,现实生活中测试样本往往是不太充足的,如果模型也能像人类学习那样利用已有的知识对不同任务举一反三,触类旁通,则只需标注少量的数据即可,迁移学习的概念正是由此引出。
在迁移学习中,有两个基本的概念:领域 (Domain) 和任务 (Task)。[4]
领域 (Domain): 是进行学习的主体,主要由两部分构成:数据和生成这些数据的概率分布。通常我们用花体 D 来表示一个 domain,用大写斜体 P 来表示一个概率分布。特别地,因为涉及到迁移,所以对应于两个基本的领域:源域 (Source Domain) 和目标域 (Target Domain)。源域 $D_s$就是有知识、有大量数据标注的领域,是我们要迁移的对象;目标域 $D_t$ 就是我们最终要赋予知识、赋予标注的对象。知识从源域传递到目标域,就完成了迁移。
任务 (Task): 是学习的目标。任务主要由两部分组成:标签和标签对应的函数。通常用花体 Y 来表示一个标签空间,用 $f(·)$ 来表示一个学习函数。 相应地,源域和目标域的类别空间就可以分别表示为 $Y_s$ 和 $Y_t$。我们用小写 $y_s$ 和 $y_t$ 分别表示源域和目标域的实际类别。
迁移学习 (Transfer Learning): 给定一个有标记的源域 $ D_s={ \lbrace x_i , y_i \rbrace }{i=1}^n $ 和一个无标记的目标域 $D_t= {\lbrace x_j \rbrace}^{n+m}{j=n+1}$。这两个领域的数据分布 $P(X_s)$ 和 $P(X_t)$ 不同,即 P(xs)≠P(xt)。迁移学习的目的就是要借助 Ds 的知识,来学习目标域 Dt 的知识 (标签)。
迁移学习在不同合成样本上的效果
本文先前实验中使用了SimGAN但效果不佳,GAN是否真的能让合成验证码学习到真实验证码的属性?论文[1]解答了我的疑问。作者对25种验证码进行了实验,最终得出结论,使用GAN去精炼合成后的样本以让其更像真实样本并不能对结果有较大提升,而迁移学习最后使用少量样本的 fine-tuning 环节才是关键所在。论文中识别验证码的整体方法流程如下图所示:
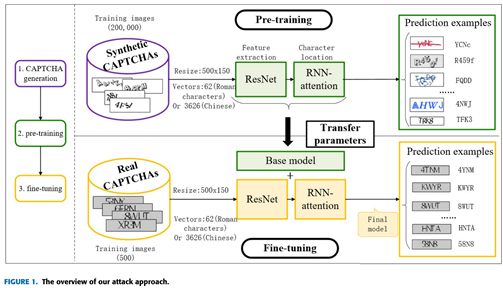
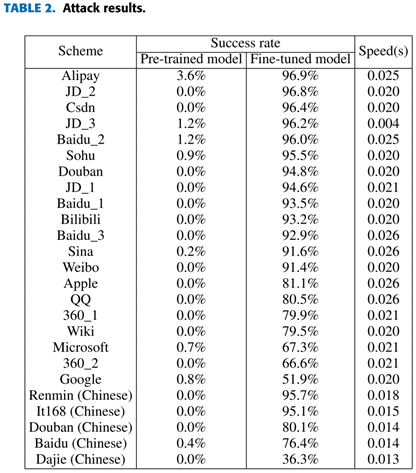
本文先前的尝试由于没有标注任何真实验证码,因此只对应了前两步,即合成验证码并使用其作为样本来预训练一个基本的模型,而没有最后的微调环节。还有一点不同之处需要注意,此处合成的验证码均为最常规的形状,并不追求与真实验证码有任何相似,fine-tuning 前后的识别成功率如下表所示,可以看到尽管之前识别率极低,但 fine-tuning 后表现都极为出色。
之前的相关工作往往费尽心思让合成的验证码更像真实验证码,甚至用上类似 SimGAN 的深度学习方法,而论文作者对此表示怀疑,为了分析合成验证码与真实验证码在外观上的相似度对识别率的影响,作者先是用传统的图像处理方法手工模拟得相似的验证码,再利用 GAN 试图让手工合成的验证码更像真实验证码,并分别进行实验,下图分别为手工模拟和 GAN 调整后的结果:
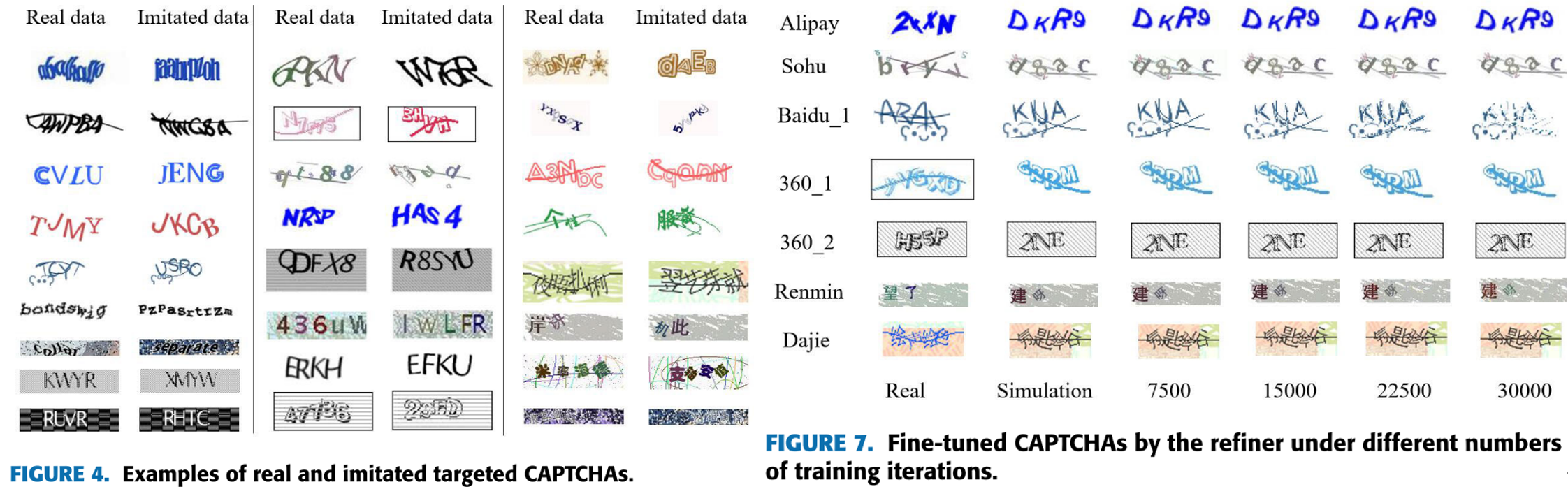
左图中第一栏第二种验证码正是本文先前尝试攻击的对象,可以看出手工调整后的验证码风格与真实验证码十分接近。而右图中 SimGAN 在肉眼上并未产生使人信服的修改效果,甚至随着训练次数增加图片可能越来越模糊以至无法辨认。
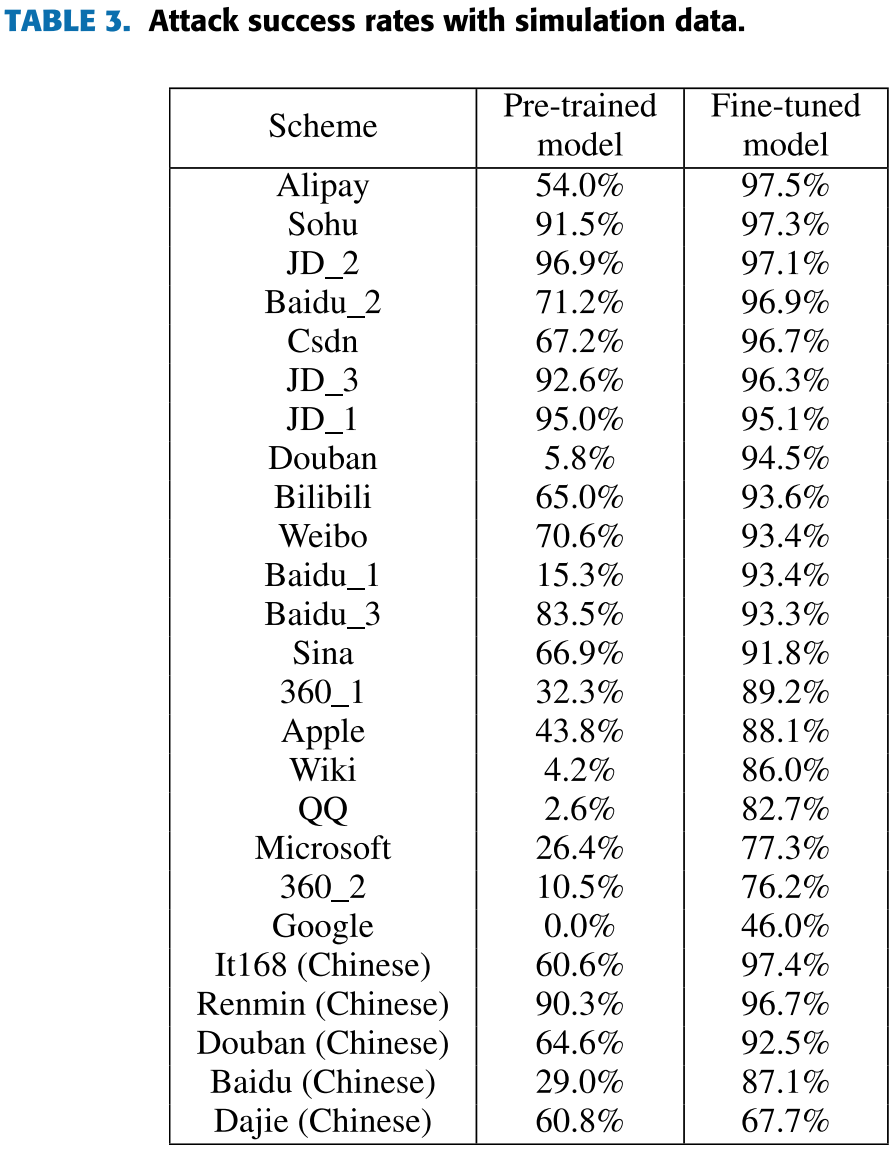
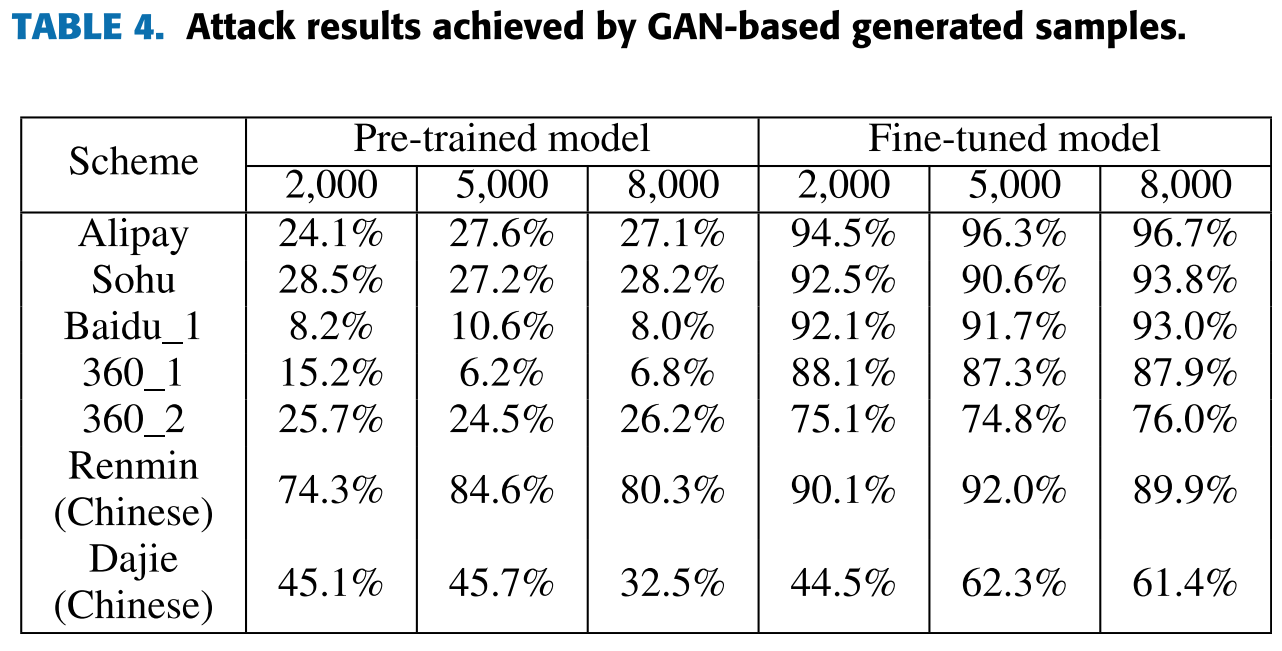
上两张表的实验结果表明,只用手工合成的相似验证码去预训练有一部分亦能达到可观的准确率,而用 GAN 继续拟合对准确率没有明显的正面影响。
因此论文作者得出了两个结论:花费时间让合成的验证码更像真实验证码对迁移学习来说是多余的无用功,最后的 fine-tuning 环节才是关键;文本型验证码确实不再安全,只需手工标注几百张样本即可以通过迁移学习达到较高的准确率。
总结与展望
由于工作中时常遇到验证码相关的风控对抗,故选择了验证码识别这一课题,在有大量标注数据的情况下其实只需套用 SOTA 模型即可。但如 Yann LeCun 所指出,无监督学习或者说自监督学习才是最大的蛋糕,所以本文坚持不手动标注真实验证码,而尝试利用 SimGAN 增强过的合成数据实现无标注的验证码识别,最开始效果完全无法接受。后来受到论文[1]启发换用了 ResNet101 作为识别模型,识别结果更加可靠。但此文也已经用实验证实了用 GAN 去增加合成数据与真实样本之间的相似程度并不能提升识别准确率,要想达到高可用的结果仍然需要少量有标签的样本进行迁移学习。
参考文献
[1] Wang, Ping, et al. “Simple and easy: Transfer learning-based attacks to text CAPTCHA.” IEEE Access 8 (2020): 59044-59058.
[2] Shrivastava, Ashish, et al. “Learning from simulated and unsupervised images through adversarial training.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[3] Ye, Guixin, et al. “Yet another text captcha solver: A generative adversarial network based approach.” Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. 2018.
[4] Jindon Wang et al., . “Transfer Learning Tutorial.” (2018).
[5] 汤战勇,田超雄,叶贵鑫,李婧,王薇,龚晓庆,陈晓江,房鼎益.一种基于条件生成式对抗网络的文本类验证码识别方法[J].计算机学报,2020,43(08):1572-1588.
[6] 曹廷荣,陆玲,龚燕红,贾惠珍.基于对抗网络的验证码识别方法[J].计算机工程与应用,2020,56(08):199-204.
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。