FuzzBuilder: 为 C/C++ library 自动构建灰盒模糊测试环境

文章目录
本文将对 ACSAC 2019 会议论文 FuzzBuilder: Automated building greybox fuzzing environment for C/C++ library 进行解读。这篇论文的主要亮点是利用单元测试为没有可执行文件的库自动生成 Fuzz 环境,通过修改 LLVM IR 以收集 seeds 并生成 executable。
论文地址:https://dl.acm.org/doi/10.1145/3359789.3359846
源码地址:https://github.com/hksecurity/FuzzBuilder
幻灯地址:https://www.acsac.org/2019/program/final/1/265.pdf
论文作者:Joonun Jang(Samsung Research), Huy Kang Kim(Korea University)
引言
Greybox fuzzing has been researched extensively, which is well known for its advantage of not only being able to test with only binarie but also useful when source code is available. Therefore, it is necessary to apply greybox fuzzing to a development process to prevent security vulnerabilities at an early stage.
Since greybox fuzzing requires execution of program, things get tough when it comes to library fuzzing. A simple approach for fuzzing a library is to generate an executable that calls library API functions and then fuzzing the generated executable. To this end, testers should manually write code that achieves high code coverage, which is a labor-intensive job requiring in-depth knowledge of libraries.
So we propose a novel approach to generate executables automatically through analysis of unit tests in project。
动机背景
Library Fuzzing
vulnerabilities in libraries can be more critical
library API: a set of functions that a library exports
library fuzzing requires a set of instructions to call library API functions with input values
提到了 Libfuzzer,只需实现 LLVMFuzzerTestOneInput(const uint8_t *data, size_t size),在其中以 data 和 size 为参数调用 library API function 即可。还需选择一个 base function,其将数据载入内存以供 library 使用,接着就能选取其他的 library API functions 以 test various features of a library.
想要自动化这个过程,生成的 executable 要能够:
- 从 fuzzer 中获取值
- 将值通过 base function 传给 target library
- 调用与 base function 相关联的不同 library API function
Function Sequence
-
a set of functions to be tested jointly
-
order of calling library API functions should be considered
-
various function sequences should be considered
Fuzzable API
-
a base library API function used to pass fuzzer inputs to library
-
generated executable should include (FA)+
Unit Test
前面的定义都是理论,此时图穷匕现,实际上 FuzzBuilder 单纯就是 generate executables and seeds by using prepared function sequences and test inputs in unit tests
a successful unit test should have:
- various function sequences
- a variety of test inputs
- high code coverage (as a result)
另外 3.2 节中还有对 unit tests 的两个假设,也是 JUnit 提倡的最佳实践:
- each test is implemented as a function
- each test is independent of each other
实验方法
文章的核心,要实现 automated generation of executable and seed,重点是 executable,注意虽然表述为 executable generation 但代码本身只是修改 LLVM bitcode,还需手动编译链接,难点主要在于熟练掌握 LLVM IR Builder API 以实现全局变量的创建和分支跳转。
Process of Seed Generation:
- Modify library FA so it will write input to a file
- Remake and execute unit test
- Store seeds to separate files
Process of Executable Generation:
- select FA
- preprocess: collecting test functions
- insert_interface: getting input from fuzzers
- remove_test: removing unnecessary test functions
- insert_operands: replacing operands of FA
用户配置如下
// https://github.com/libexpat/libexpat
// seed.conf,收集 seeds 时使用
{
"targets" : [ [ "XML_Parse", 2, 3 ]],
"files" : [ "xmlparse.bc" ]
}
// bug.conf,生成 exe 时使用
{
"targets" : [ ["XML_Parse", 2, 3] ],
"files" : [ "runtests.bc" ],
"tests" : [ "test_" ],
"skips" : ["test_alloc_nested_groups", "test_ABC"]
}
其中 targets 就是 Fuzzable API 的列表,函数名后跟着两个分别是 buf 和 len 在该函数 args 中的位置(从1开始计数),files 是要读取并修改的 LLVM bitcode 文件,会作为 Module 加载到 IRReader 中。test 和 skip 只有在生成 exe 时使用,前者用于粗略获取单元测试函数,后者用于排除。
收集 seed 就是要获取单元测试的输入,修改 library FA,用 LLVM IRBuilder 在函数的 entry block 插入一段 BB,将输入数据写入 COLLECT_PATH 指定的文件中,再 Br 回原来的 BB 继续执行,具体实现在 IRWriter::collect() 中。
将修改后的 .mod.bc 编译为 .o,并 ar 到整个库的 .a 上,再运行单元测试,数据就会被写入到指定文件,运行 seed_maker.py 会再读取并整齐地保存到 seeds 目录下。
(一个坑点是收集完 seed 后 .o 仍处于被修改状态,记得用原来的代码重新编译,否则后续 Fuzz 的输入通通都会写入文件,直接挤爆硬盘)
生成 executable 需要在单元测试的 IR 上插桩,先让 IRReader 遍历 modules 按用户配置的 tests 和 skips 收集所有 targets(不是 FA 而是 test_ABC) 以备后面插桩使用。然后在 modules 中找到 entry function(即运行单元测试的入口 main 函数),IRWriter::interface() 先在对应 module 中创建 global 的 buf 和 size,set CommonLinkage 并初始化为0, 然后在 entry block 插入 BB,在循环中以 4K 为单位 read stdin 到栈上的 tmp,并每次在堆上分配更大的空间,拷贝之前的 global buf 和新读入的 tmp,将 global buf 原来的空间释放后指向新分配的空间,直到 read 不足 4K 或返回 -1,这样就插入了一个 interface 将标准输入全部读到 global buf 中。
可将插入 interface 的 LLVM IR 翻译为如下 C 代码
char* fuzzbuilder_buf;
int fuzzbuilder_size;
int main() {
entry1:
char *tmp = alloca(4096); // GEP in llvm
read_n1 = read(0, tmp, 4096);
if (read_n1 == -1) goto link;
else goto entry2;
entry2:
char* p = calloc(read_n1 + 1, 1);
fuzzbuilder_buf = p;
memcpy(p, tmp, read_n1);
fuzzbuilder_size += read_n1; // load, add, store
if (read_n1 == 4096) goto entry3;
else goto link;
}
entry3:
goto entry4;
entry4:
read_n2 = read(0, tmp, 4096);
if (read_n2 == -1) goto link;
else goto entry5;
entry5:
char *p2 = calloc(fuzzbuilder_size + read_n2 + 1, 1);
memcpy(p2, fuzzbuilder_buf, fuzzbuilder_size);
memcpy(p2 + fuzzbuilder_size, tmp, read_n2);
free(fuzzbuilder_buf);
fuzzbuilder_buf = p2;
fuzzbuilder_size += read_n2;
if (read_n2 == 4096) goto entry4;
else goto link;
link:
// original code ...
再将分支跳转简化为如下循环:
char* fuzzbuilder_buf;
int fuzzbuilder_size;
int main() {
char *tmp = alloca(4096);
int read_n;
while((read_n = read(0, tmp, 4096)) != -1) {
char * p = calloc(fuzzbuilder_size + read_n + 1, 1);
memcpy(p, fuzzbuilder_buf, fuzzbuilder_size); // 1st: memcpy(p, 0, 0)
memcpy(p + fuzzbuilder_size, tmp, read_n);
free(fuzzbuider_buf);
fuzzbuilder_buf = p;
fuzzbuilder_size += read_n;
if (read_n != 4096) break;
}
// original code ...
}
接着 insert_fuzz_to_tests(targets),对每个 function(变量名是 targets 但实际上是单元测试中的 test_ABC 而非 library 中的 FA)进行 IRWriter::fuzz(),遍历 function 中的所有 CallInst 和 InvokeInst,若 inst->getCalledFuncion() 即 callee 在 targets 中则将 inst 加入集合,最后遍历集合中的 inst,读取配置中对应 target 的 fuzz 和 len 参数位置,用 gv_buf 和 gv_s 分别替换,即调用 inst->setArgOperand(idx, &v),这样 test_XX 中对 FA 的调用都被修改为传入 global buf 中的数据,也就是之前从 stdin 读入的数据,重新编译后就可以用 AFL 进行 fuzz 了。值得注意的是 IRWriter::fuzz() 中还把 __assert_fail 与 abort 全部移除了,论文中只在末尾 Discussion 处提到,可能是后来实现的。
此外 insert_skip_to_tests(skips) 会遍历 skip functions,只处理返回类型为 void 或 int 的,原有内容全部清除,直接返回 void 或 0
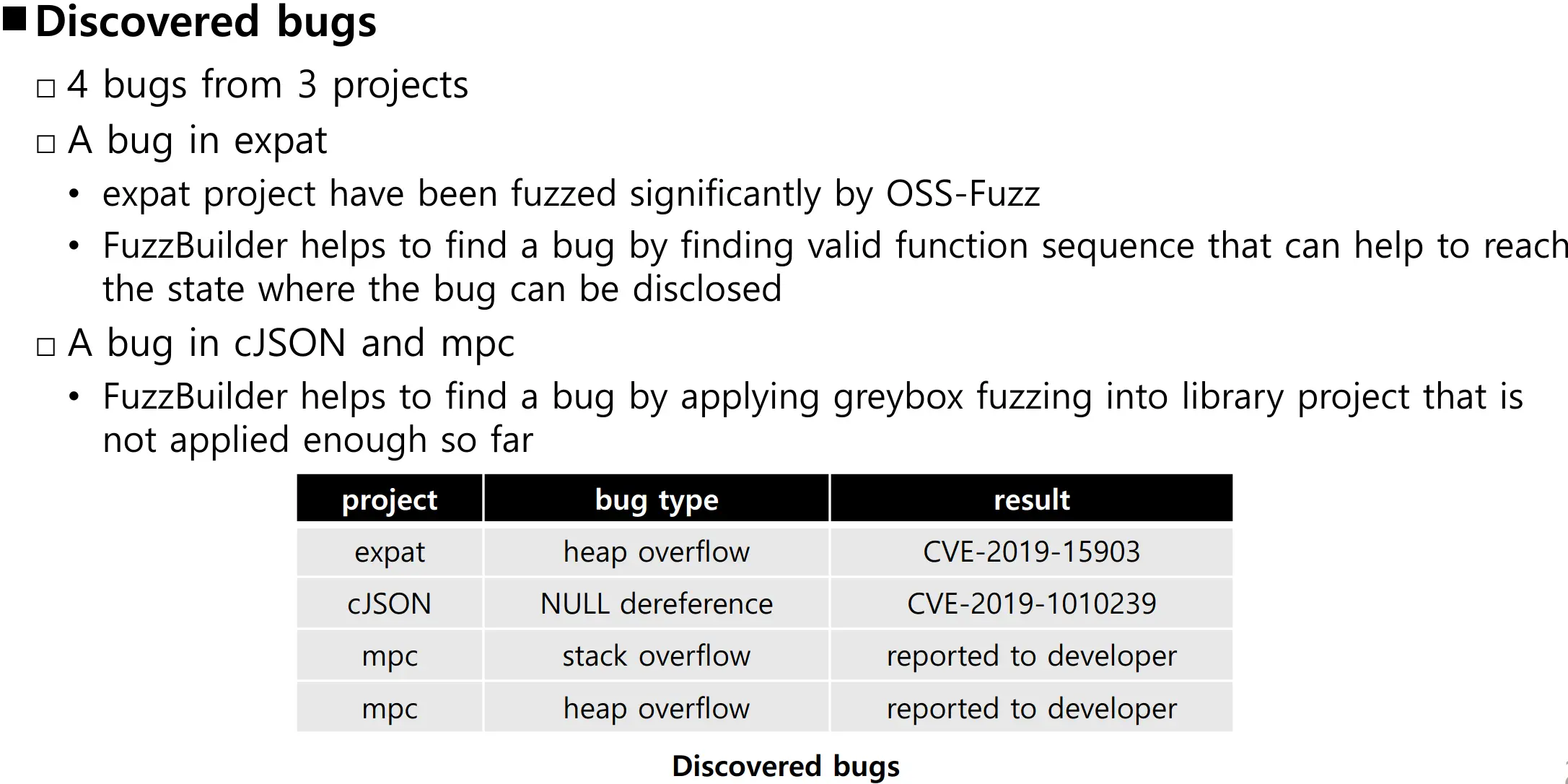
效果验证
Experiment Design:
- The efficiency of generated seeds
- The effectiveness of generated executables
- The effectiveness of FuzzBuilder as a bug finding tool.
Metrics:
- Line coverage
- Number of discovered bugs
Comparative Evaluation: OSS_Fuzz
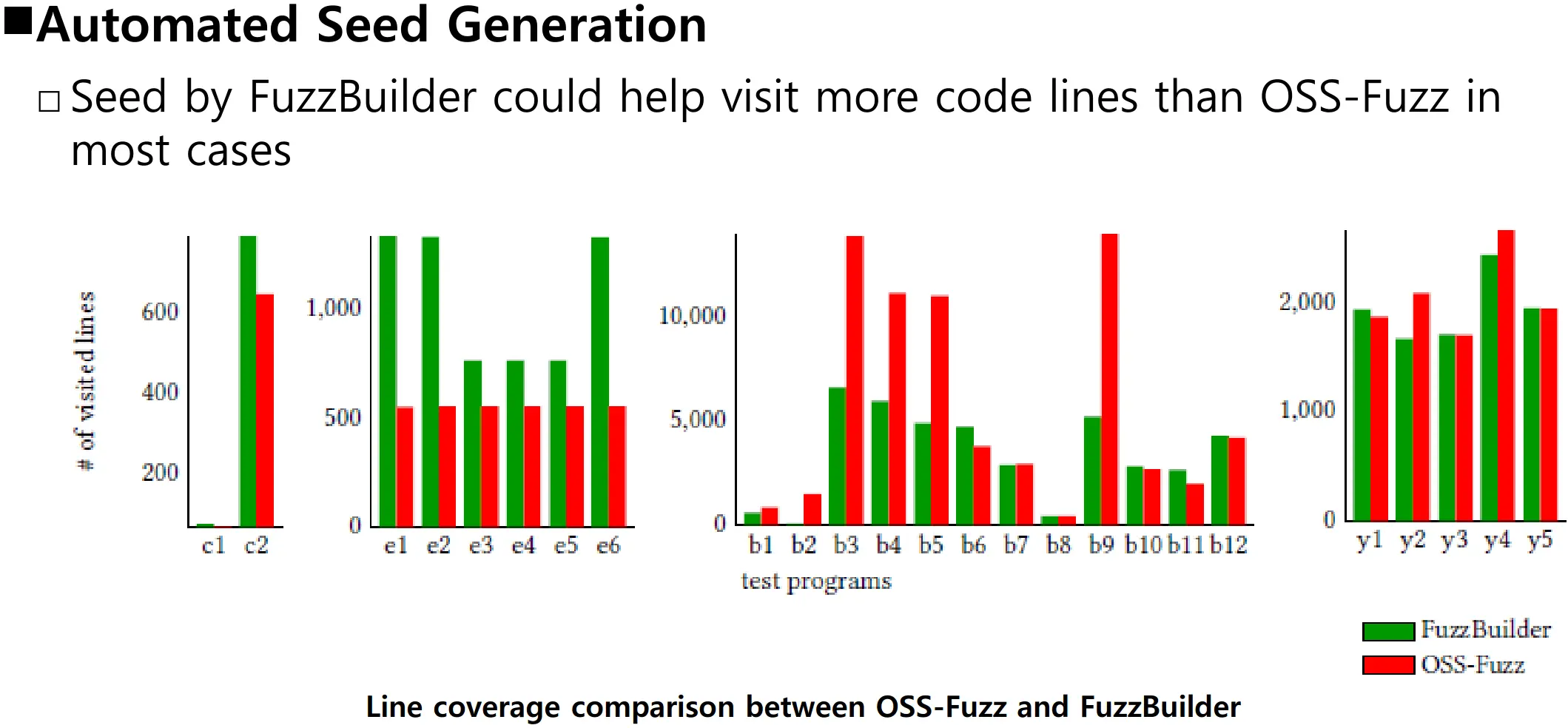
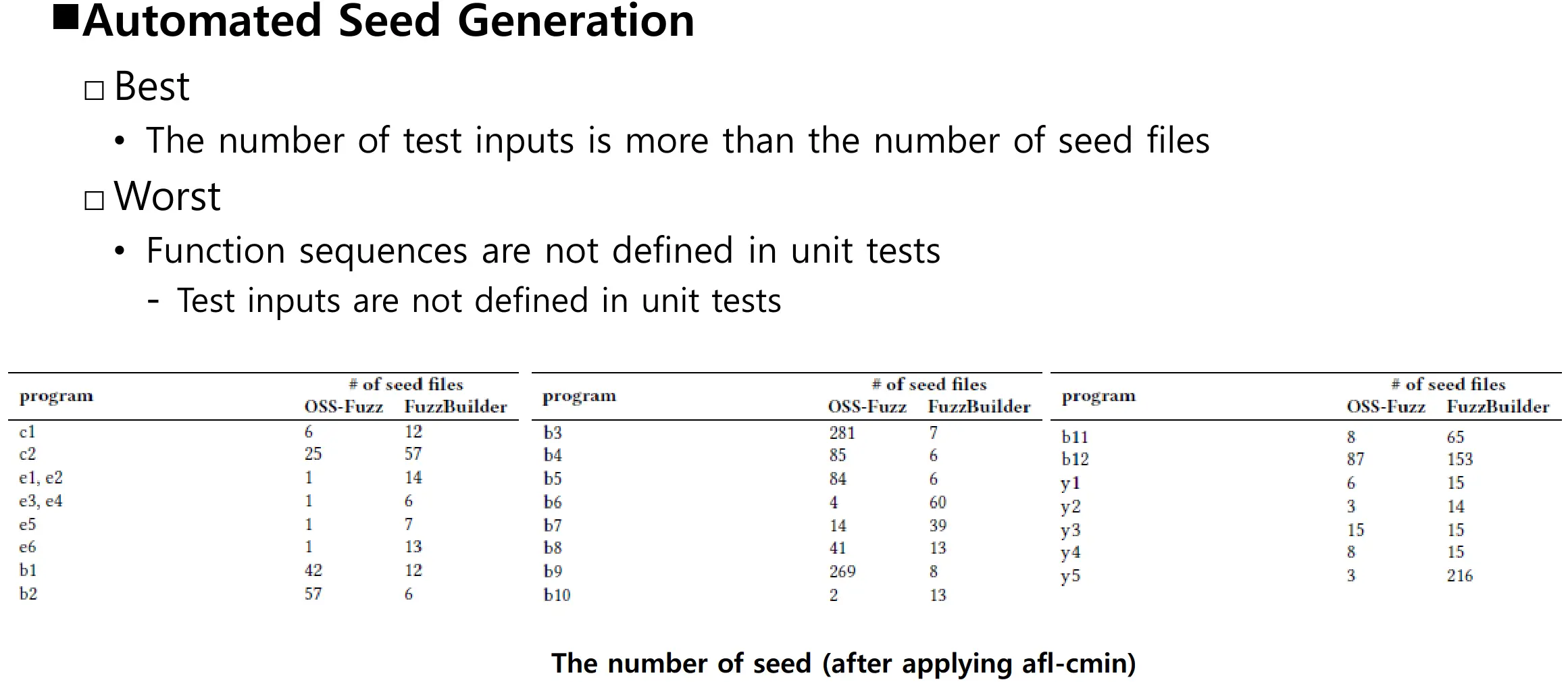
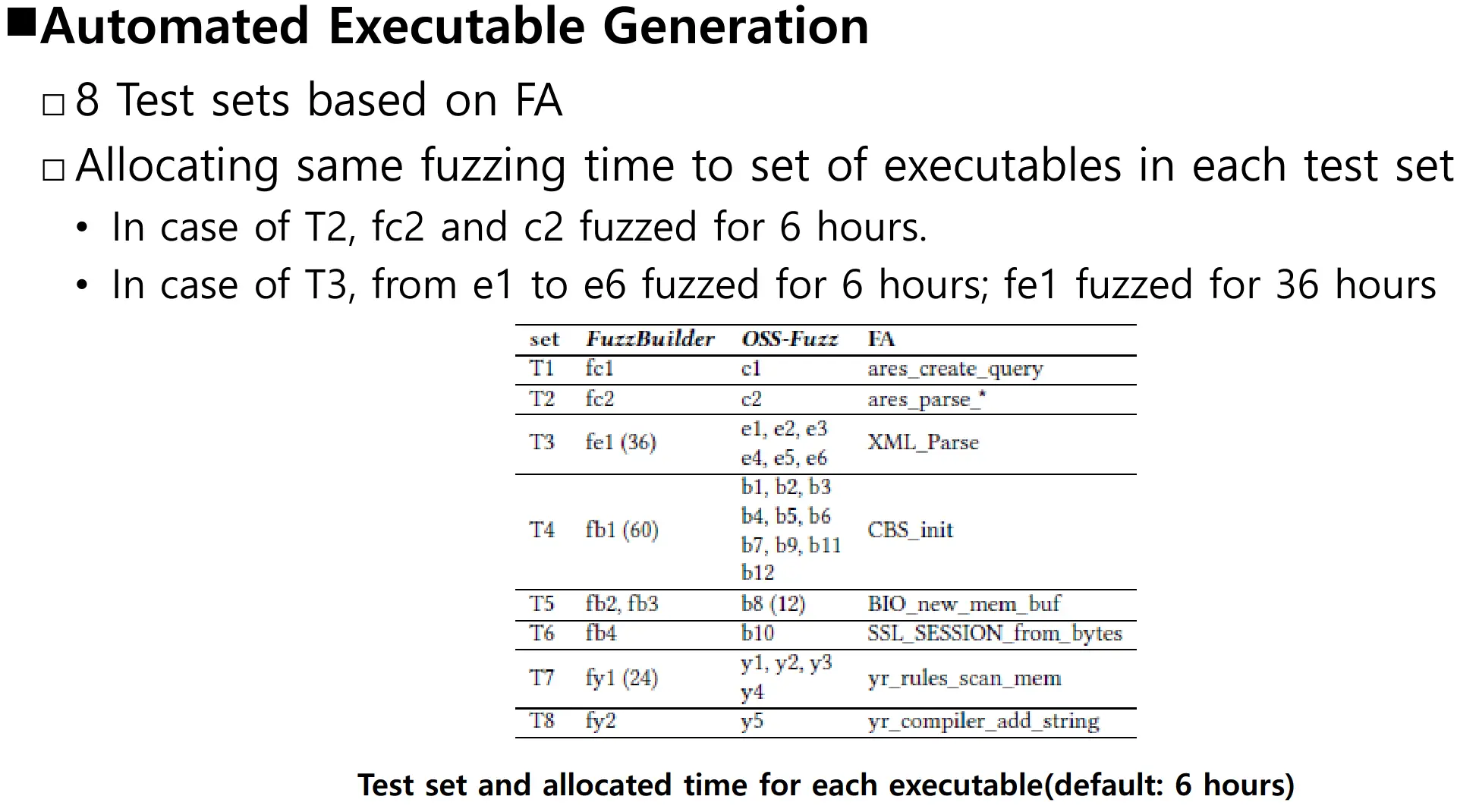
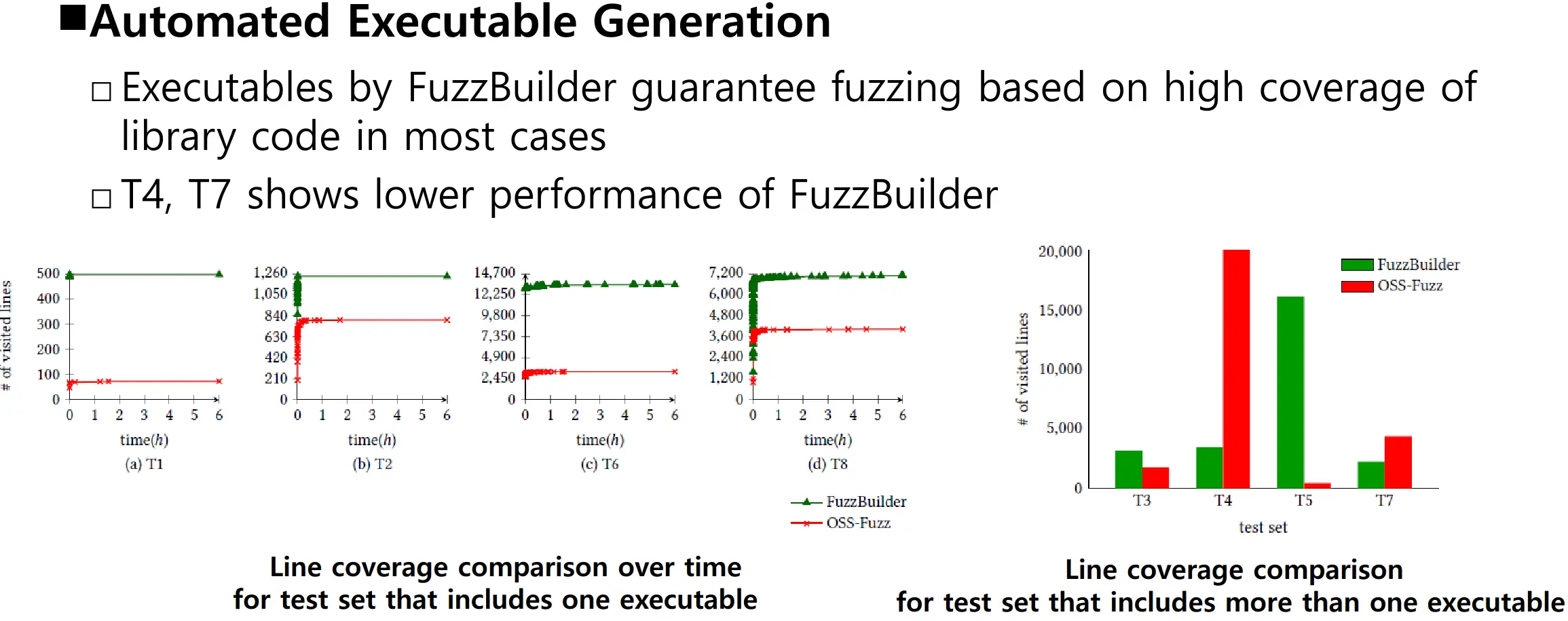
相关讨论
Related Work 就是提了下 Greybox Fuzzing 和 OSS-Fuzz,Fuzz Builder 的好处在于能从单元测试的输入自动得到较有效的 seeds,并且也不像 Libfuzzer 那样要手写 fuzz 代码。
Future discussion:
- FA automation
- Optimization of generated executable
- Errors in unit test
- Expansion of input value types
个人感觉 errors in unit tests 是比较实际的,一些单元测试不会考虑 unexpected value 或者用 assert abort 来退出,这样 fuzzer 的输入很可能导致程序异常终止从而被视为 bug,但这不算 library 本身的 bug 所以导致 false alarm。
个人总结
一句话概括就是 make unit test fuzzable,在 library FA 处插桩以收集单元测试的数据作为 seed,在测试代码的 entry 插桩以创建从 fuzzer 获取数据的 interface 并更改所有调用 FA 的指令使其传入来自 fuzzer 的全局 buf 数据,就得到了可供 fuzzer 运行的代码。
论文前期铺垫了很多 Fuzzable API, Function Sequence 之类的概念设定,但 2.4 节之后引入 unit test 却没有很好地联系,感觉前后有些割裂。
感谢作者公开了代码并尽可能地给出了使用示例,代码为 C++ 编写,使用了单例模式,整体较为清晰,但 IRReader 和 IRWriter 中函数似乎有些冗余,尤其是 targets = get_functions_to_fuzz() 的过程,加上变量命名为 targets 但其实是 tests,给理解造成障碍。
原本的代码基于 LLVM 6.0,而自己机器已经到 LLVM 13 了,不想使用提供的 Docker 环境,于是入门了 LLVM IR 的基本概念,微改代码以适配 LLVM 的 API 变动,为了更好地在 VS Code 中调试还配置了 CodeLLDB。
参考资料
LLVM Language Reference Manual
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。