RAZOR: Software Debloating

文章目录
RAZOR: software debloating
论文信息
原文作者:Chenxiong Qian, Hong Hu, Mansour Alharthi, Pak Ho Chung, Taesoo Kim, and Wenke Lee, Georgia Institute of Technology
原文标题:RAZOR: A Framework for Post-deployment Software Debloating
发表会议:USENIX SECURITY ‘19
原文链接:https://www.usenix.org/system/files/sec19-qian.pdf
代码链接:https://github.com/cxreet/razor
问题背景
商业软件的功能越做越多,终端用户只用到一小部分,软件往往显得臃肿,这不仅浪费耗费系统资源,还带来了更多攻击面,而 software debloating 可以解决此问题。
但以往的工作需要获取软件源码,而用户往往只有分发部署后的二进制程序,且不同用户所需的功能各异,所以 post-deployment 软件更加具有实际效用。
post-deployment software debloating 有以下两个挑战:
- 如何让不了解软件内部的用户选择要保留和移除的功能
- 如何修改二进制程序,在删除无用功能的同时保留所需
对于第一个挑战,可以让用户提供输入样例,但即使输入完全相同,多次执行时也可能产生不同的程序执行路径,所以要识别出 necessary-but-not-executed 的那部分程序,即 related-code,很难获得完全正确的答案,所以作者使用了启发式的方法,以四个层次递进,逐步扩大覆盖范围。
对于第二个挑战,收集完 related-code 后,就可以重写二进制程序,通用的二进制重写依赖于可靠的反汇编结果和完整的 CFG,故而较为困难。对于 software debloating 而言仅需重写要执行的那部分功能,通过 trace 就可获得 CFG,因而可以实现二进制重写。
系统设计
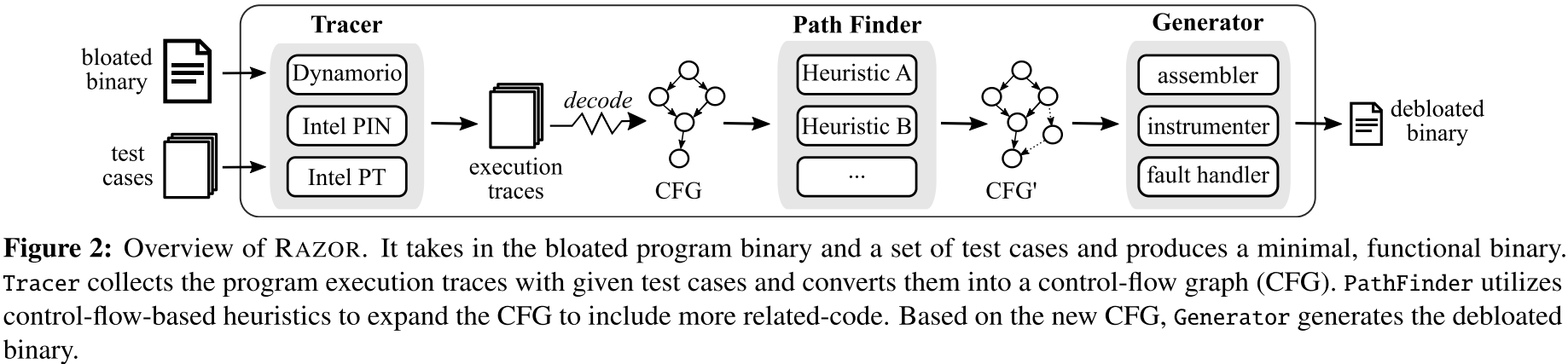
如图所示,即 Tracer, Path Finder 和 Generator
Execution Trace Collection
Tracer 以所给测试数据执行程序,记录三种控制流信息:
- Executed instructions (memory addr & raw bytes)
- Conditional Branches
- Indirect Calls/Jumps
Instruction-level recording 可以应对动态生成的代码,但效率不高,考虑到现实中的程序大多只有静态的代码,所以 Tracer 先从 basic block level 开始记录,检测到疑似动态代码生成的特征再切换到 instruction level。
Tracer 综合运用了基于软件的工具 (Dynamorio) 与基于硬件的工具 (Intel PIN 和 Intel PT),前者普适性好但性能较差,后者高效但无法保证信息完整,三种 trace 技术可能产生不同的程序执行,用户可以选择最适合的或合并 trace 结果来获得更好的代码覆盖度。
收集完 trace 结果后,就能反汇编二进制程序并构建所需的部分 CFG。
Heuristic-based Path Inference
由 Tracer 获得的 CFG,用启发式方法扩展 CFG,获得 related-code
- zCode,无新增指令,CFG 上只连边不加点
- zCall, 无新函数调用,若 non-taken 分支不含任何 call 指令,则加进 CFG
- zLib, 无任何额外的库函数,若 non-taken 分支只 call 同 binary 的函数或已被 call 的库函数,则加进 CFG
- zFunc, 无不同功能的库函数,若 non-taken 分支 call 的外部函数不涉及新的 functionality,则加进 CFG
算法如下图所示

Debloated Binary Synthesization
- 先将原始二进制程序按照 CFG 反汇编,生成包含所有必要指令的伪汇编(pseudo-assembly)
- 修改伪汇编创建有效的汇编文件,symbolize basic blocks, concretize indirect calls/jumps, and insert fault handling code
- 编译汇编文件成为包含必要的机器码的目标文件(object file)
- 复制目标文件中的机器码到原始二进制程序中一个新的代码段(code section)
- 修改新代码段来修复对原始代码和数据的所有引?
- 设置原始代码段不可被执行,仍保留在 debloated 后的程序中(可能还会被读取?比如实现 switch 的 jump table)
具体实现
代码开源在 https://github.com/cxreet/razor
有提供使用说明 https://github.com/cxreet/razor/wiki,从测试小程序到 coreutils 都有
docker pull chenxiong/razor:0.04 可以直接体验
效果验证
3 个 benchmark,前两者用软件方式 trace,后两者用硬件方式 trace:
- 29 SPEC CPU2006,包含 12 个 C 程序,7 个 C++ 程序和10个 Fortran 程序
- 论文 CHISEL 中用到的 10 个 coreutils 程序
- Firefox 和 FoxitReader
在以下五个方面和 CHISEL 对比:
- Code Reduction: 从精简效果上看 CHISEL 略胜一筹,但其影响程序鲁棒性
- Functionality: RAZOR 使用启发式方法扩展 related-code 后,测试功能完全正常,CHISEL 则有 wrong operation, infinite loop, crash, missed output 等问题
- Security: 选择一些 CVE,部分是可在对应 binary 上利用的,部分已经被修复。CHISEL 消除代码的策略激进,消除了更多 CVE 但导致一些原本已修复的 CVE 又可被利用,相比之下 RAZOR 更稳健。另外消除 ROP gadget 数量也是 CHISEL 略胜,因为 RAZOR 更关注防止 forward-edge control-flow attack,这种攻击利用函数指针而不是返回地址
- Performance: RAZOR 的构建速度在秒级,远胜 CHISEL。运行时开销也平均只增加 1.7%,主要是由于 indirect call concretization
- Practicality: 在 Firefox 和 Foxit Reader 这两个大型应用上测试打开网页和 PDF,在启发式方法下都取得了不错的效果
讨论与相关工作
Best-effort inference: 启发式方法虽然不能保证 completeness 和 soundness,但广泛用于二进制分析和重写中
Control-flow Integrity (CFI): 控制流完整性检测和 Software Debloating 其实是互相促进的,debloating 可实现粗粒度的 CFI,而 RAZOR 也利用了 binCFI 中的技术来做优化。
Removing original code: 其实目前 RAZOR 还保留原本的 code section 只是设成 read-only,因为其中的数据可能还会被读取,比如 llvm 会对 switch 语句在 code section 中生成 jump table,需要被 indirect jump 读取。要完全移除也可以先分析对 code section 的读取,再在重写时将数据 reloacate 到新的 data section 并更新相关代码来访问新的位置。
相关工作有针对 library, source code, container, hardware 的 debloating,以及 delta debugging,在这些方面 RAZOR 也有可能提供新的思路。
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。