MAB-Malware 多臂老虎机生成恶意软件对抗样本

文章目录
摘要:机器学习方法广泛被用于各种分类问题,恶意软件分类正是其中一种。对于图像分类的对抗样本攻击已经有很多成功的案例,而对恶意软件分类器的对抗样本则较少有人研究。本文将介绍恶意软件分类的相关背景及先前的对抗样本工作,并详细描述 AsiaCCS 2022 的论文 MAB-Malware,使用多臂老虎机模型生成对抗样本,最后基于 OpenAI Gym 复现其工作并进行相应评估。
关键词:强化学习;对抗样本;恶意软件分类;多臂老虎机
问题背景
恶意软件和病毒层出不穷,如何在不执行样本的情况下仅通过静态特征识别恶意软件是一个重要问题,传统的基于签名匹配的方法已经无法识别,各大杀毒软件公司都开始采用机器学习方法去地识别恶意软件,且取得了不错成效。
机器学习方法识别恶意软件本质上就是一个二分类问题,和图像分类一样,都需要经过原始数据获取,特征工程和模型学习预测这几个过程,大致的流程如下图所示:
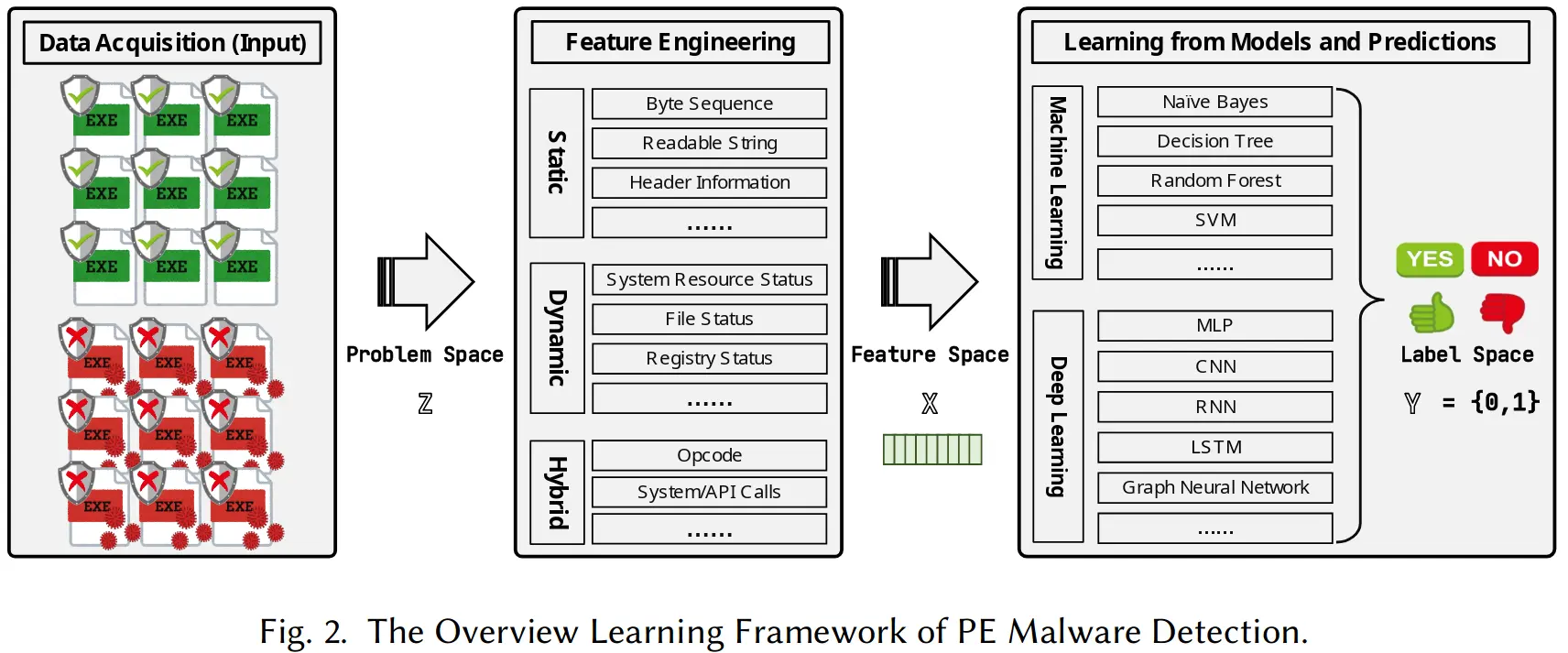
但大量工作已经证明,只需对恶意软件做微小的改动,基于机器学习的方法就很容易被绕过,这就是对抗样本攻击。之前对抗样本工作主要集中在图像分类领域,恶意软件的对抗样本则更加特殊,哪怕只改动一比特也有可能破坏 PE 文件结构或让恶意功能失效,这就是所谓的 problem-feature space dilemma,图片的特征大多可被表示为像素值矩阵,而 PE 恶意软件的特征不太固定且难以找到从 problem space 返回到 feature space 的逆映射。因此恶意软件的对抗样本通常不直接按字节改动文件,而是使用一系列行动(actions),每一个 action 都能在不破坏原本功能的情况下改变恶意软件,比如在末尾增加多余的一节(section)。因此要生成恶意软件的对抗样本,就是找到对应的 actions 及 contents 来造成误分类。
针对静态恶意软件分类器的对抗样本攻击并不新鲜,先前的工作有用基因算法(genetic programming),蒙特卡洛树搜索(genetic programming),deep Q learning 等,尽管这些方法具有一定的效果,但都存在三个问题:
-
首先,这些技术都以有状态(stateful)的方式生成对抗样本,搜索空间巨大而难以训练出模型
-
其次,现存技术大多只是学习一个选取 action 的策略,内容则随机选取的,但其实具体内容和对抗样本生成的有效性会有很大关系
-
最后,当成功生成一个对抗样本,reward 奖励给所有 actions,但往往只有一小部分关键的 action 是关键的,多余 actions 其实可以被移除
UCR 的 Heng Yin 教授发表于 AsiaCCS 2022 的论文 MAB-Malware 提出了新的强化学习框架,将对抗样本生成这一问题建模为经典的多臂老虎机(multi-armed bandit)问题,实现了 stateless, content-aware, precise reward assignment 这三大目标。

MAB 问题
多臂老虎机(multi-armed bandit,MAB)是一个经典的强化学习问题,体现了典型的探索-利用困境(exploration-exploitation dilemma),老虎机有多条臂,每条臂对应一个奖励概率分布,玩家每轮可以选择一条臂以获得奖励,最终目标是在需要在有限的轮数内让收益最大化。
多臂老虎机模型在现实世界有着广泛的应用,包括广告展示,医学试验和金融等领域。比如在推荐系统中,事先不知道用户商品的反应,我们需要每次推荐给用户某个物品,来最大化用户的购买量,这就是一个典型的多臂老虎机问题。
在恶意软件样本生成领域,有很多 action 可以改变恶意样本的特征,其中许多都需要内容载荷(content payload)来起作用,比如添加一个新的 section 需要来自良性样本的内容,内容对逃逸成功率有很大的影响,对抗样本攻击就是要找到一系列 <action, content> 组合来最大化生成逃逸样本的概率,每一组 <action, content> 就是一个 slot machine,整个多臂老虎机可以看成一个 <M,R> 元组,其中 M 是 slot machine 的集合,R 是对应的奖励分布(reward distribution)集合 {θ1, …, θk},假设共有 k 个机器,t 次尝试机会,目标就是拉动机器获取最大化奖励。
在本文提出的框架中,区分 generic machine 和 specific machine 这两种机器,攻击刚开始时我们不知道哪些内容更有效,因此有必要用 generic machine 来随机生成内容,并探索特定 action 下适用的不同内容,而 specific machine 则可以利用特定内容生成更多对抗样本。
汤普森采样
在生成恶意软件对抗样本时,会遇到延迟反馈(delayed feedback)的问题,即需要等待识别器的扫描结果,如果采用确定性算法如置信度上界(upper confidence bound, UCB),在结果出来之前会一直选择值最高的那个,从而因为信息过时造成低效的尝试,我们使用在延迟反馈环境下鲁棒性更强的汤普森采样来解决此问题。假设每一机器的奖励服从对应的贝塔分布(beta distribution),即 M ~ Beta(ɑ, β),ɑ 和 β 分别是成功和失败的次数。
每次迭代选择 action 时,对每一机器 M,从其贝塔分布 Beta(θ;ɑ, β) 采样奖励值,选择值最高的机器作为下一步。当 ɑ 和 β 值较小时,机器 M 的不确定性较高,即使其平均奖励可能较小,仍然有高概率获得更大的值,因此更倾向选择去探索新机器,当尝试次数增多后,机器的 ɑ 和 β 值增大,不确定性减小,最终会选择利用奖励较高的机器,这样就在 explore-exploitation 之间取得了平衡。
Binary Rewriter
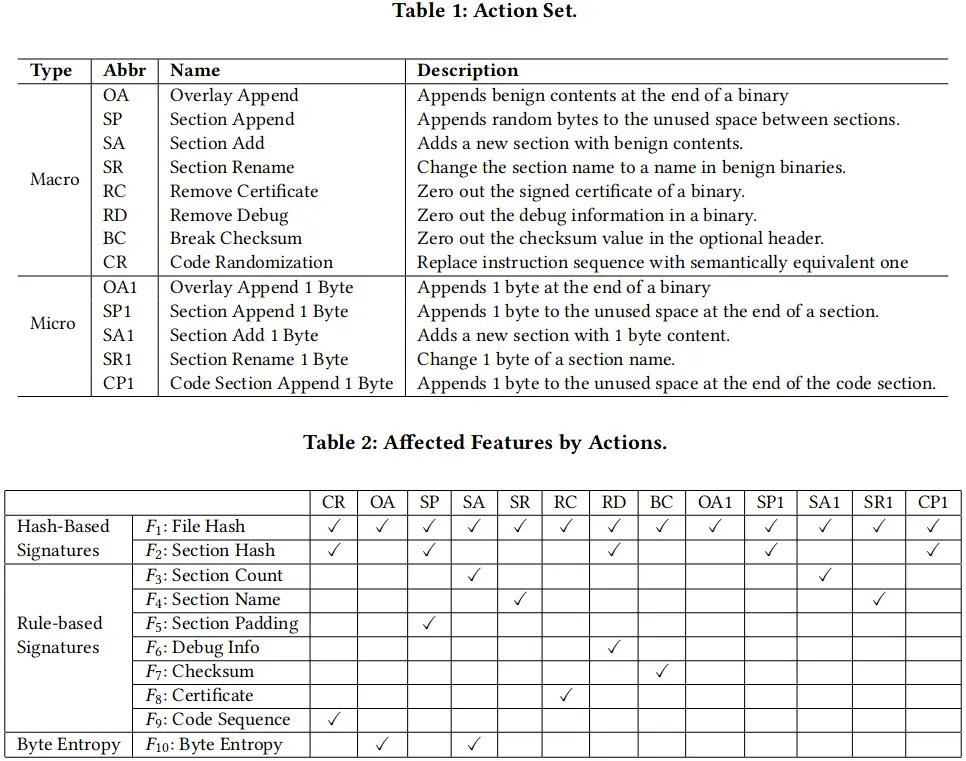
作者用 pefile 这个库重新实现了 13 个 action,但与先前工作不同的是,作者区分了 macro-action 和 micro-action 这两种概念,因为一个 marco-action 可能影响恶意样本的多个 feature,如果另一 action 只影响了其中一部分,便认为其是原 action 的 micro-action。作者实现了 5 种 micro-action,和对应的 macro-action 相一致,不过只添加 1 字节的内容,比如 SA (section add) 会改变文件的哈希值、section 数量和字节熵(byte entropy)这三个特征,而 SA1 则只改变前两个特征。具体的 action 和特征列表如下图所示:
Binary rewriter 的工作流程如下算法所示,先初始化 8 个 generic machine,即 8 条 arm,ɑ 和 β 值均设为 1,每次迭代时对每一机器从其贝塔分布中采样一个值,选取值最高的 machine 应用于样本,若逃逸失败则增加 β 值,直到生成了一个逃逸成功的样本,便使用 Action Minimizer 来去除多余的 machine,只留下一系列 essential machine,对其中的 machine 增加其 ɑ 值,若是 generic machine 则用其内容创建对应的 specific machine,若是 specific machine 则给对应 generic machine 也增加其 ɑ 值。

Action Minimizer
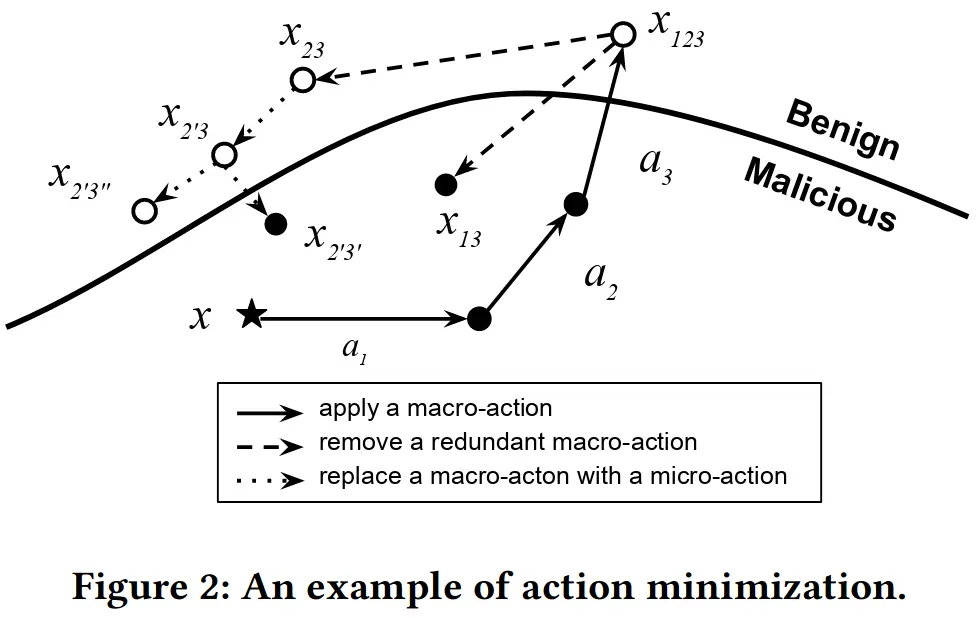
恶意样本逃逸成功后,可以移除多余的 action,并用 micro-action 代替 macro-action 来产生特征改变较小的对抗样本。如下图所示,对恶意样本 x 连续施加 a1, a2, a3 三个 action 后得到了逃逸样本,不施加 a1 仍然能够逃逸,因此可以移除这一无用 action,而对 a2, a3 尝试用 micro-action 替代,最终得到最小化的样本。
下面是 minimize 算法的严格描述:

通过将 marco-action 分解成更多小的 micro-action,还能帮助理解逃逸成功产生的原因,下图就说明了如何根据 micro-action 逃逸的结果判断分类器应用了哪些 feature,这样对攻击做出解释的同时也能帮助防守方有针对性地改进自己的模型。

实验评估
被攻击的目标模型是 Malconv 和 EMBER,数据集是 VirusTotal 上选择的 5000 个样本
首先是对抗样本生成上的比较
- 直接对比逃逸效果,结果显著好于采用 GAMMA 基因算法的 SecML-Malware,而 Gym-Malware 的结果几乎和随机选择没有区别,这是因为模型搜索空间太大,Q-learning 根本学不到有意义的知识。
- 由于不同工作的 action set 有差异,为证明本文用 MAB 算法选择 action 的有效性,在同样的 action set 下换用 MCTS 方法选择 action,结果表明 MAB 算法大大改进逃逸率,而 MCTS 方法相比随机选择并无太多改进,这体现了之前 stateful 对抗样本生成方法很难在很大的搜索空间中找出逃逸的路径。
- 作者还在商业 Anti-Virus 软件上进行了测试,尽管这类软件不一定使用机器学习方法,MAB-malware 还是能达到接近一半的准确率,超过其他两者
在功能保存度上 MAB-Malware 也表现更好,根据作者的实验结果,先前使用 LIEF 库的工作生成的逃逸样本大多都没法执行或表现有异,而作者用 pefile 库则能更好地保证恶意样本的功能性。
此外作者还总结了逃逸样本中最常见的 action sequence,发现 Overlay Append (OA) 能显著干扰被攻击的两种基于 ML 的分类器,而 Anti-Virus 软件则易受 SA1 影响,说明它们把 section 数量作为分类指标。
最后作者还测试了所生成的对抗样本的迁移性,尽管 Malconv 和 EMBER 分别采用 CNN 和 决策树两种不同的模型,在其中一个模型上逃逸成功样本中也有超过 10% 能在另一个模型上逃逸。
代码复现
作者将代码开源于 https://github.com/bitsecurerlab/MAB-malware,并提供了 Docker 镜像 wsong008/mab-malware
MAB-Malware 的代码没有采用任何 ML/RL 框架,只有作为攻击对象的 Malconv 代码使用了 PyTorch 来定义和加载模型。
或许是由于文中提到的分类器结果存在延时问题,代码采用了多线程的工作方式,classifier, rewriter 和 minimizer 三个线程同时进行。
classifier 持续扫描 minimizer_scan_folder 和 rewriter_scan_folder 这两个文件夹里的文件,若检测为恶意则删除,否则改名加上 .benign 后缀。
rewriter 先调 samples_manager.get_initial_pending_list(),不断循环 sample_manager.get_next_sample() 随机取一个 sample 并使用 bandit.get_next_arm() 经过汤普森采样返回一个 arm,arm.pull(sample) 得到新样本路径并 set_current_exe_path(),然后复制到 rewriter_scan_folder(),当获取不到 sample 或每 pull 一定次数时 update_working_list(),直到没有 remain sample 则跳出循环。
minimizer 和 rewriter 共享一个 samples_manager,在主循环中持续检查是否有逃逸样本,然后调 minimize_evasive_sample 对所有 STATUS_EVASIVE 的 sample 用 action_subset 重设改后的路径, update_evasive_list 则根据 scan_status 为 deleted 或 pass 判断是否逃逸并更新 bandit
我们的目标是使用 Gym 构建通用的恶意软件对抗样本评估环境,需要实现 Env 和 Agent 两个接口,Gym 官方是没有 Multi-Armed Bandit 的模型,参考了网上一些代码似乎无法很好地描述本文的模型,这或许是由于 Multi-Armed Bandit 本身是一个很多样的问题,根据 Introduction to Multi-Armed Bandits 中的定义,本文的 MAB 模型应当属于 bandit feedback 和 adversarial rewards。
花费数月理清代码逻辑并不断调试,以各种 hack & dirty 方式解决报错,我终于成功将原来分散在 classifier,rewriter 和 minimizer 三个线程中的代码强行在一个 MAB Gym 环境的 step 方法中调用,而 agent 的关键代码则只有一行,由 bandit 的汤普森采样选取 action,这里我最开始还酿成了大错,给 agent 和 env 分别初始化了不同的 bandit,使得 agent 选取 action 时并未根据汤普森采样,所幸我在观察 arms 的 alpha 和 beta 值时觉得异常而发现了这处低级错误。
def step(self, action: Arm):
self.turns += 1
output_path = action.pull(self.sample)
self.sample.set_current_exe_path(output_path)
self.sample.append_arm(action)
self.score = self._scan(self.sample)
if self.score < self.malicious_threshold: # successful evasion
self.sample.status = SAMPLE_STATUS_EVASIVE
reward = self.original_result - self.score
self.history[self.sha256].output = True
self.history[self.sha256].reward = reward
self.history[self.sha256].evaded_path = self.sample.current_exe_path
self.history[self.sha256].actions = self.sample.current_applied_arm_subset
episode_over = True
stop_minimize = (self.sample.status == SAMPLE_STATUS_MINIMAL) or self.sample.seq_cur_x >= len(self.sample.list_applied_arm)
while stop_minimize is False:
self.samples_manager.minimize_evasive_sample()
self.score = self._scan(self.sample)
self.samples_manager.update_evasive_list()
stop_minimize = (self.sample.status == SAMPLE_STATUS_MINIMAL) or self.sample.seq_cur_x >= len(self.sample.list_applied_arm)
if self.sample.status == SAMPLE_STATUS_MINIMAL:
reward = self.original_result - self.score
self.history[self.sha256].reward = reward
self.history[self.sha256].evaded_path = self.sample.current_exe_path
self.history[self.sha256].actions = self.sample.current_applied_arm_subset
self.sample.scan_status = SCAN_STATUS_PASS
elif self.turns >= self.maxturns: # game over
reward = self.original_result - self.score
episode_over = True
self.history[self.sha256].output = False
self.history[self.sha256].reward = reward
else:
reward = self.original_result - self.score
episode_over = False
self.sample.status = SAMPLE_STATUS_WORKING # so sample can be added to working list later
self.samples_manager.update_working_list() # FIXME: do necessary operations in gym instead of calling update_working_list
return self.sample, reward, episode_over, self.history[self.sha256].__dict__
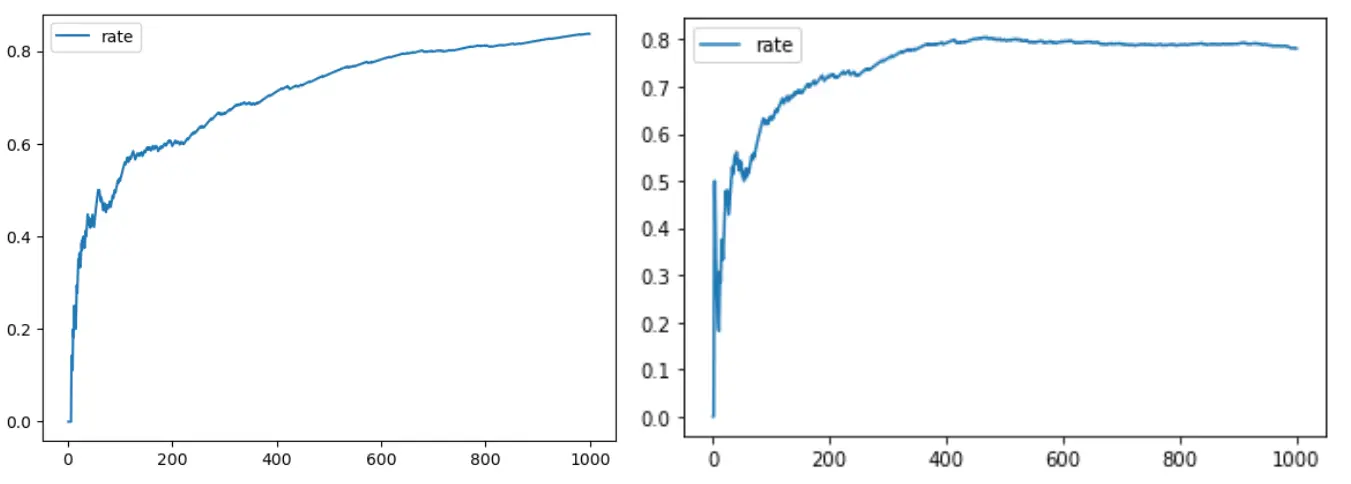
最终设置在每个样本最多尝试 60 个 step,每次最多连续 10 个 action 的情况下,在 1000 个恶意样本上实验得到约 80% 的逃逸成功率,多次测试后发现相同参数下多次实验的逃逸率结果差距可达 10%,可能是能否生成非常有效的 specific machine 具有较强的随机性。而比较违反直觉的是加大每个样本 step 的轮次尽管能使得逃逸率提升较快,却并不能保证最终逃逸率突破极高的上限。
如下左右两图分别为设置尝试60个step和100个step的逃逸率结果:
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。