用合成 bug 评估KLEE:Characterizing and Improving Bug-Finders with Synthetic Bugs

KLEE 是知名的符号执行引擎,甚至还有专门的学术会议,第三届 KLEE Workshop 于本月 15-16 日在伦敦召开,大家也可以选择线上免费参会。今天分享的这篇名为 Characterizing and Improving Bug-Finders with Synthetic Bugs 的论文就对 KLEE 发现 bug 的能力做了评估,论文发表于 SANER ‘22,其作者 Brendan Dolan-Gavitt 正是 LAVA 这一自动合成 bug 语料库的开发者,论文中用 LAVA 和 Juliet 这两种合成 bug 来评估 KLEE 的效果,通过分析哪些 bug 未能被发现来揭示 KLEE 的可靠性(soundness)问题。
LAVA 是一个源码级别的自动 bug 注入工具,可以向 coreutils 这种 C 程序注入数千个漏洞,尽管支持插入多种 bug,本文中只考虑内存安全 bug 如指针越界读写。
Juliet Test Suite 由 NSA 开发,包含 64099 个测试用例,按 Common Weakness Enumeration (CWE) 系统分类,其中大多数程序不需要输入且只有一条路径。由于其原本是用于测试静态分析工具,所以用于 KLEE 时需要很多微调,比如调用 klee_make_symbolic 来将程序中的 rand 函数调用符号化。
本文中的测试分为两部分:首先是对小型程序的测试,作者期待 KLEE 能够探索小型程序的所有路径,所以一旦有 bug 未被发现都表明 KLEE 的可靠性有问题;现实世界中的大型程序则可能有更丰富的特性,不过 KLEE 可能在给定时间内可能难以执行到 bug,作者修改了 KLEE 让其可以根据给定的路径以 concolic 的方式执行,这样就能测试 KLEE 在走到正确路径的情况下能否找到注入的 bug。
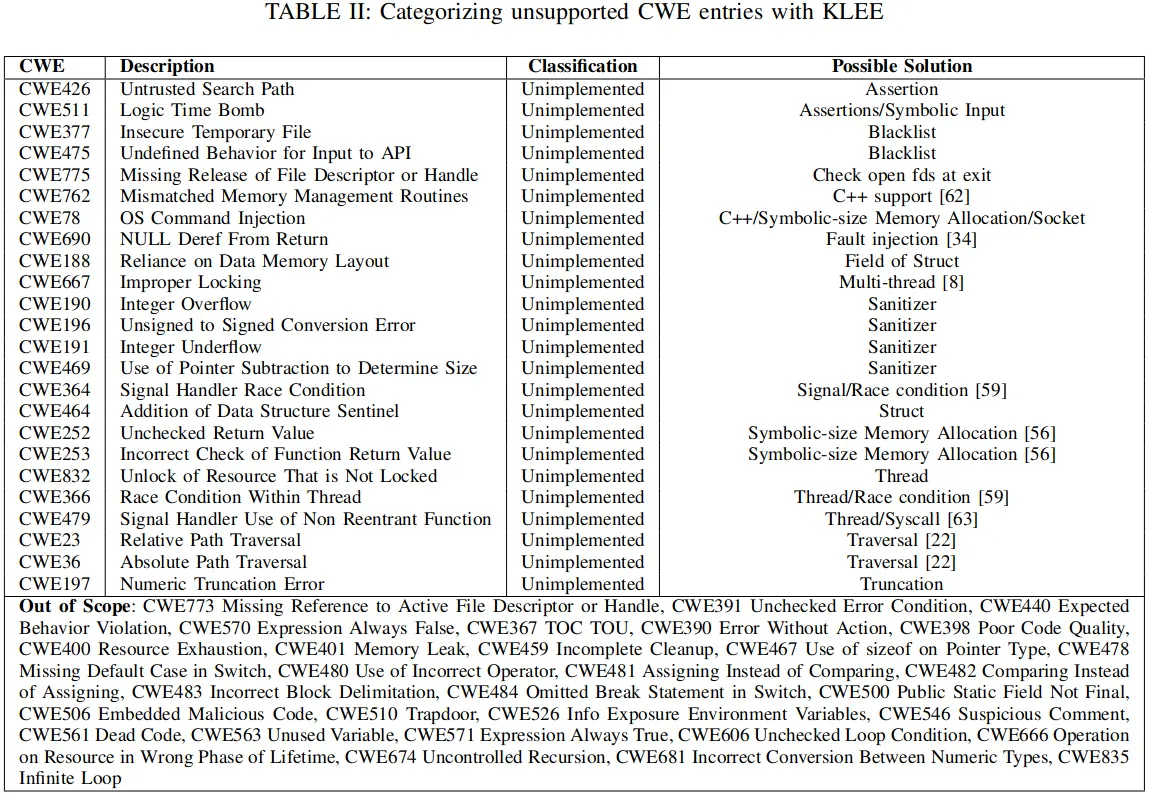
具体来说,对于小型程序测试,作者编写了 62 行的 C 程序 toy.c,用 LAVA 自动生成了 159 个含有单个 bug 的变体。除此之外,还从 Juliet Test Suite 中选取了能够用 wllvm 成功编译得 LLVM bitcode 的程序,并筛去其中含有 KLEE 明确不支持特性的程序,有一些 CWE 类型比如 (CWE546: Suspicious Comment) 根本不在 KLEE 这种作用于 LLVM IR 的工具的应用场景内,标记为 out of scope,还有些 CWE 理论上可被 KLEE 支持但需要额外修改,标记为 unimplemented,详见下表,最终仅保留 17603 个测试用例。
对于现实软件的测试则选取了 coreutils 中的十个程序,注入了两千多个 bug,并选择了 200 个具有独特 attack point 的 bug,配有触发 bug 的输入。尽管 KLEE 有自己的 concolic 模式让用户提供输入文件,但作者发现光是这一输入文件不足以让 KLEE 按特定路径执行,于是自己修改了 KLEE,先 trace 一遍记录相关信息,再次运行 Executor::fork 时就不真的 fork 而是挑选和 trace 相匹配的后继状态。
在用 LAVA 自动生成的 159 个小型 bug 程序变体上,KLEE v1.4 只发现了 68 个,而 KLEE v2.2 则发现了 150 个。为了理解为什么 KLEE v1.4 漏报了许多漏洞,作者将插入的 bug 分为两类,一些是插在用户自定义的函数(即程序 main 源码)中,另一些是插在外部函数(如 libc 函数)调用的参数中。KLEE v1.4 漏报的 bug 大部分属于后者,因为其不检查传递给外部函数的指针,剩余少数漏报的 bug 则多是由于缺乏浮点数支持,KLEE v2.2 漏报的 5 个也是如此。

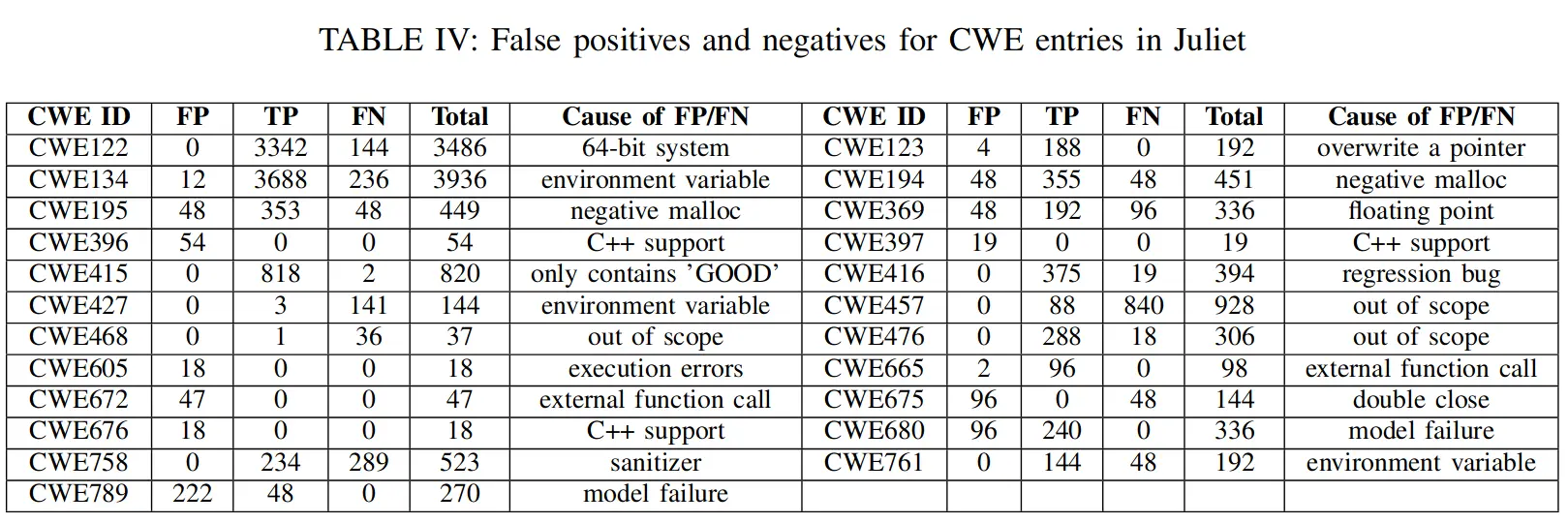
由于 LAVA 注入的 bug 都是简单的指针错误,作者还在 Juliet Test Suite 上进行测试,在总共 17603 个支持的测试用例上,KLEE 报告了 18868 个 true postive, 732 个 false positive,和 2013 个 false negative,报告 bug 比测试用例还多是因为设置了 KLEE 记录所有的错误,只有在一个 testcase 没有生成任何报告的情况下才认为其是 false negative,即漏报。
作者发现部分 false positive(误报)是由于程序本身执行错误,还有一些是因为不支持 C++ 或是 Juliet Test Suite 本身的问题。部分 false negative(漏报)则是由于 KLEE 实现上的一些限制,因为 Juliet Test Suite 原本针对静态分析器故而没有提供触发输入,难以使用 concolic execution 来执行可触发 bug 的路径,导致无法区分漏报究竟是由于尚未探索到路径还是 KLEE 本身的可靠性问题。
而如前所述,在用 LAVA 给 coreutils 插入 bug 时使用了 concolic execution 以让 KLEE 按触发 bug 的路径执行程序,排除了路径爆炸问题造成的影响。最终结论是 KLEE 在现实应用上检测 bug 的能力尚可,主要问题是 KLEE 默认采用的 uClibc 和 glibc 的差异较大,比如 glibc 中 FILE 结构体的某一指针成员在 uClibc 的对应成员不是指针,这可能造成误报或漏报。
根据以上实验结果,作者对 KLEE 给出了中肯的评价:尽管 KLEE 在浮点数、外部函数和 C++ 语言特性支持上存在一些限制,但这些都是文档中明确表示的已知缺陷,除此之外用户不太会遇到其他问题,作者认为这恰恰是 KLEE 作为一个成熟的符号执行引擎的标志。因此,当使用 KLEE 测试现实软件时,应当更多专注于特性的支持和与其他库的交互,比如实现更多系统调用和支持多线程,这些工作已经部分存在于一些研究向的 fork 中,希望能被添加到上游并持续维护。
最后作者还提出了对符号执行引擎 test suite 的迫切需求,不同于针对静态分析工具的 Juliet Test Suite,它应该:
- 带有触发输入(triggering inputs)作为基准真相(ground truth)
- 包含广范围的 bug,囊括多种 CWE
- 关注能被符号执行检测的 bug 种类,避免或标注出仅适用于静态分析的 bug
- 将程序输入和不确定性来源标准化,使之能容易地被符号化
作者也坦承自己的工作存在一些不足,比如在大型程序上的测试仅限 coreutils,KLEE 在这上面的表现早已被重点优化过。不过除了数据集的选取问题外,本文的研究重点是否也有待商榷?路径探索和约束求解本应是符号执行的长处,完全忽略这两者而直接在合成测试集上评估所谓 bug findng 能力,到底能具有多大的现实意义呢?
论文地址:https://messlab.moyix.net/papers/evalklee_saner22.pdf
Juliet Test Suite 地址:https://github.com/yh570/Juliet_test_suite
LAVA Corpus 地址:https://github.com/yh570/LAVA_corpus
Concolic KLEE 地址:https://github.com/yh570/Concolic_klee
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。