静态分析检测漏洞真的有效吗:An Empirical Study on the Effectiveness of Static C Code Analyzers for Vulnerability Detection

文章目录
今天给大家推荐的是来自 ISSTA 2022 的一篇论文 An Empirical Study on the Effectiveness of Static C Code Analyzers for Vulnerability Detection,作者是慕尼黑工业大学的 Stephan Lipp, Sebastian Banescu 和 Alexander Pretschner,作者在真实 CVE 数据上对静态分析工具检测漏洞的效果做了详细的评估。
论文地址:https://doi.org/10.1145/3533767.3534380
Artifacts 地址:https://doi.org/10.5281/zenodo.6515687
视频地址:https://www.youtube.com/watch?v=N6kePNadUV8
研究动机
静态分析技术由于较低的部署成本和性能开销被广泛用于代码安全检测中,不过高误报率(high false positive rate)是其广为人知的一大缺点。至于其究竟能否有效地检测出代码中的漏洞,也就是假阴性率(false negetive rate)是否够低,则是另一个问题,之前较少有人研究。本文作者发现先前的工作都是在 Juliet Test Suite 这种人造数据集上进行,其中人为合成的漏洞本来就很容易发现,所以静态分析工具都宣称能达到 80% 左右的检测率。然而静态分析器在检测实际漏洞时的效果如何?不同的静态分析工具有有何优劣,组合起来在效果上有何提升?哪些种类的漏洞更容易被发现?这就是本文想要回答的三大问题。
研究对象
静态分析器
作者将静态分析技术分成两类:语法分析(Syntactic Static Analysis)只是搜寻一些可能引入漏洞的代码,比如对memcpy这种函数的调用,所以对源代码应用即可,无需编译信息;语义分析(Semantic Static Analysis)需要考虑控制流或数据流信息,所以要先将源代码转换成抽象语法树、调用图和控制流图等更抽象的表示,尽管语义分析一般会伴随着不可判定性问题,但它可能发现更多复杂的漏洞。
具体到本文中将研究的静态分析产品,作者选取了 6 款 C/C++ 静态分析工具,其中 5 款是开源的,即Flawfinder (FLF), Cppcheck (CPC), Infer (IFR), CodeChecker (CCH), CodeQL (CQL),剩下一款隐去姓名的商业软件,称为 CommSCA (CSA),它们都实现了 SOTA 的静态分析技术,被广泛用于之前的 benchmark 工作中。
漏洞分类
Common Weakness Enumeration (CWE) 是一种漏洞分类系统,每种漏洞类型都被赋予唯一的编号,不同类型之间还可具有树形层级关系,顶部的 CWE 更多代表抽象的 class,底部的 CWE 则表示更具体的漏洞 type,不同静态分析器中对漏洞的描述都可以被归到 CWE 体系中。
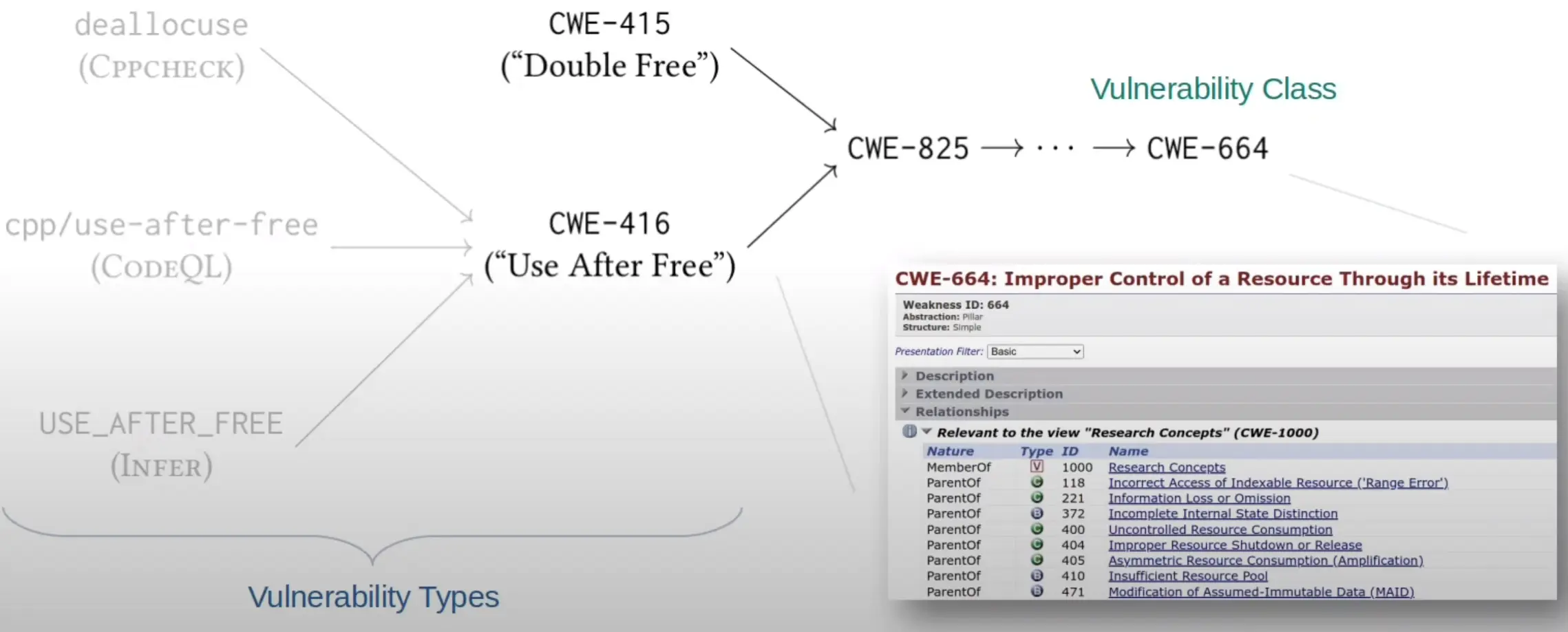
因为 C 语言中很多漏洞都紧密关联,比如 double-free (CWE-415) 和 use-after-free (CWE-416) 非常接近,都属于 Expired Pointer Dereference (CWE-825)。有些静态分析器可能给出了接近但不完全相同的 CWE,这种情况应当算作成功识别,所以比较时粒度不能太细,作者根据 Goseva-Popstojanova 和 Perhinschi 的现有工作 把相近的 vulnerability types 归为 classes,最终确定了如下 5 个 CWE 大类:
- Improper Control of a Resource Through its Lifetime (CWE-664)
- Incorrect Calculation (CWE-682)
- Insufficient Control-Flow Management (CWE-691)
- Improper Check or Handling of Exceptional Conditions (CWE-703)
- Improper Neutralization (CWE-707)
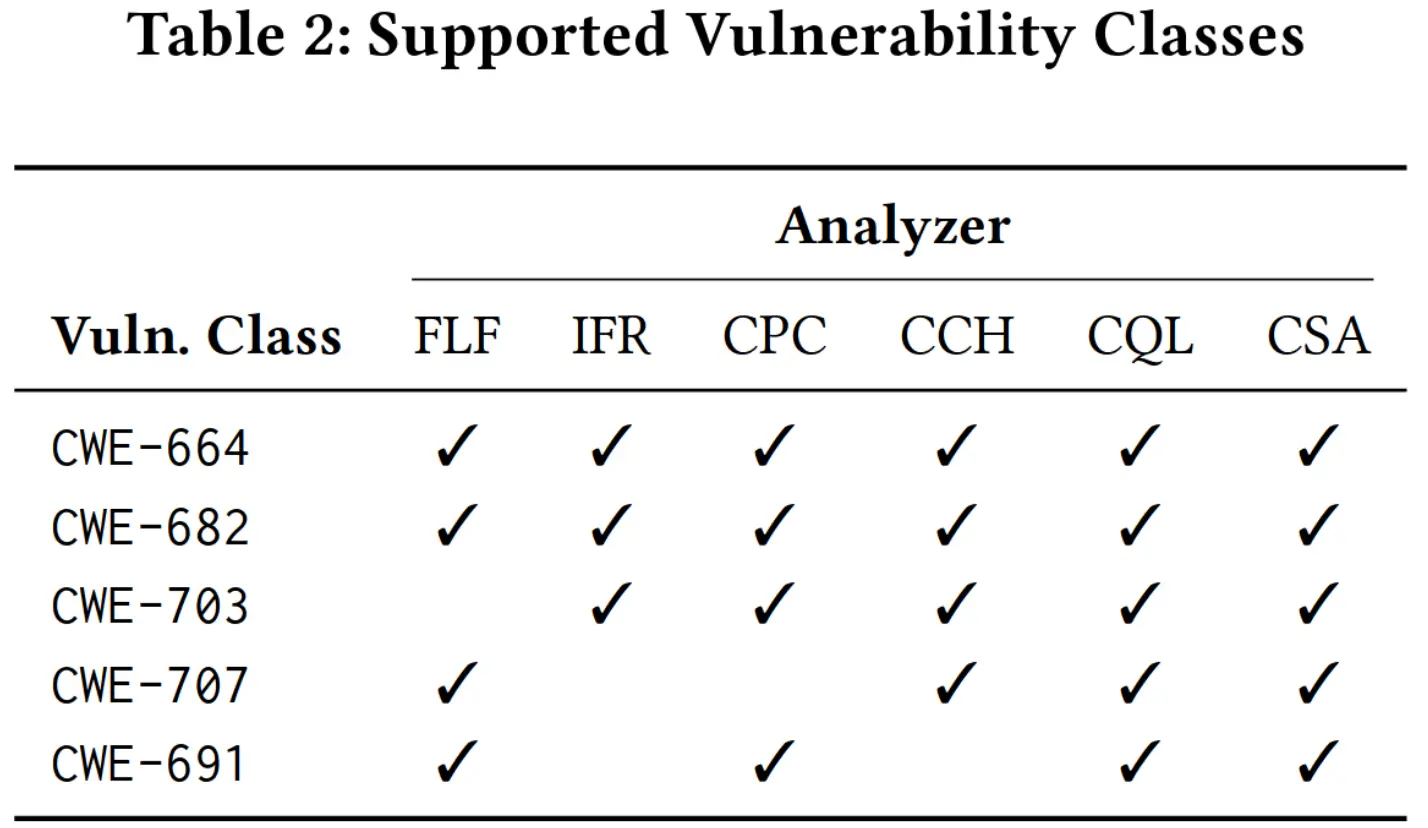
需要注意,不是每种 CWE 都被所有静态分析器支持的。作者调研了各个静态分析器的文档,对于每个 CWE 大类,若文档中提到能检测该类别中一种具体的漏洞,就认为静态分析器支持该种 CWE 大类,最终得到如下 CWE 支持性表格:
漏洞数据
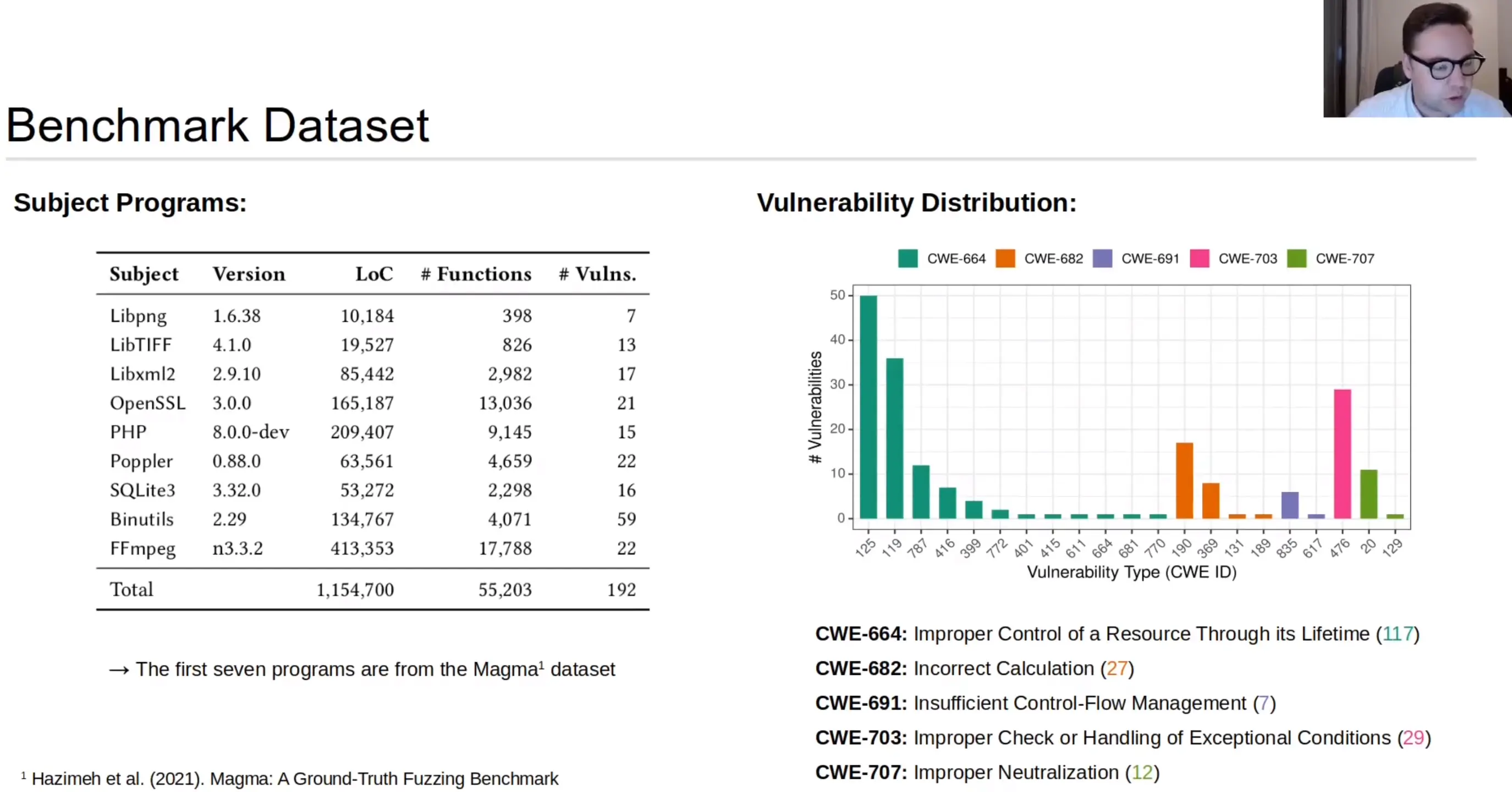
现有工作基本都是基于 Juliet Test Suite 这种合成数据集,而真实 bug 的数据集数量较少且种类单一或根本就没指出漏洞类型,还好有 Magma 这个原本针对 fuzzer 设计的 benchmark 是从 CVE 报告构建而来,包含了118 个漏洞,还使用了 front-porting 技术,能把在老版本软件中已发现的 bug 插入到新版本中。
本文除了利用 Magma 数据集,还额外包括了 binutils 和 FFmpeg 中的 81 个 non-front-ported 真实漏洞。
实验设计
评估粒度
静态分析工具一般会标注代码中错误显现的位置而非漏洞产生的根源,而CVE 报告对 fault (root cause) 和 error (manifestation) 的呈现并不是非常的完整,比如有些 CVE 给出 patch 的 commit 记录,从中可发现 fault 的根本原因,而有些只是在文字描述中给出了 error 显现的位置,所以本文决定将漏洞位置的粒度设置在函数的层面上。
为了确保评估结果有效,fault 和 error 应当出现在相同的函数中,否则对于只指出 fault 位置的 CVE 就无法判断静态分析是否检测成功,作者采用 Fault-Error Conformity (FEC) 这个指标,即对于某一漏洞,fault和 error 重叠的函数个数与 error 所在函数的个数之比,结果如下表:
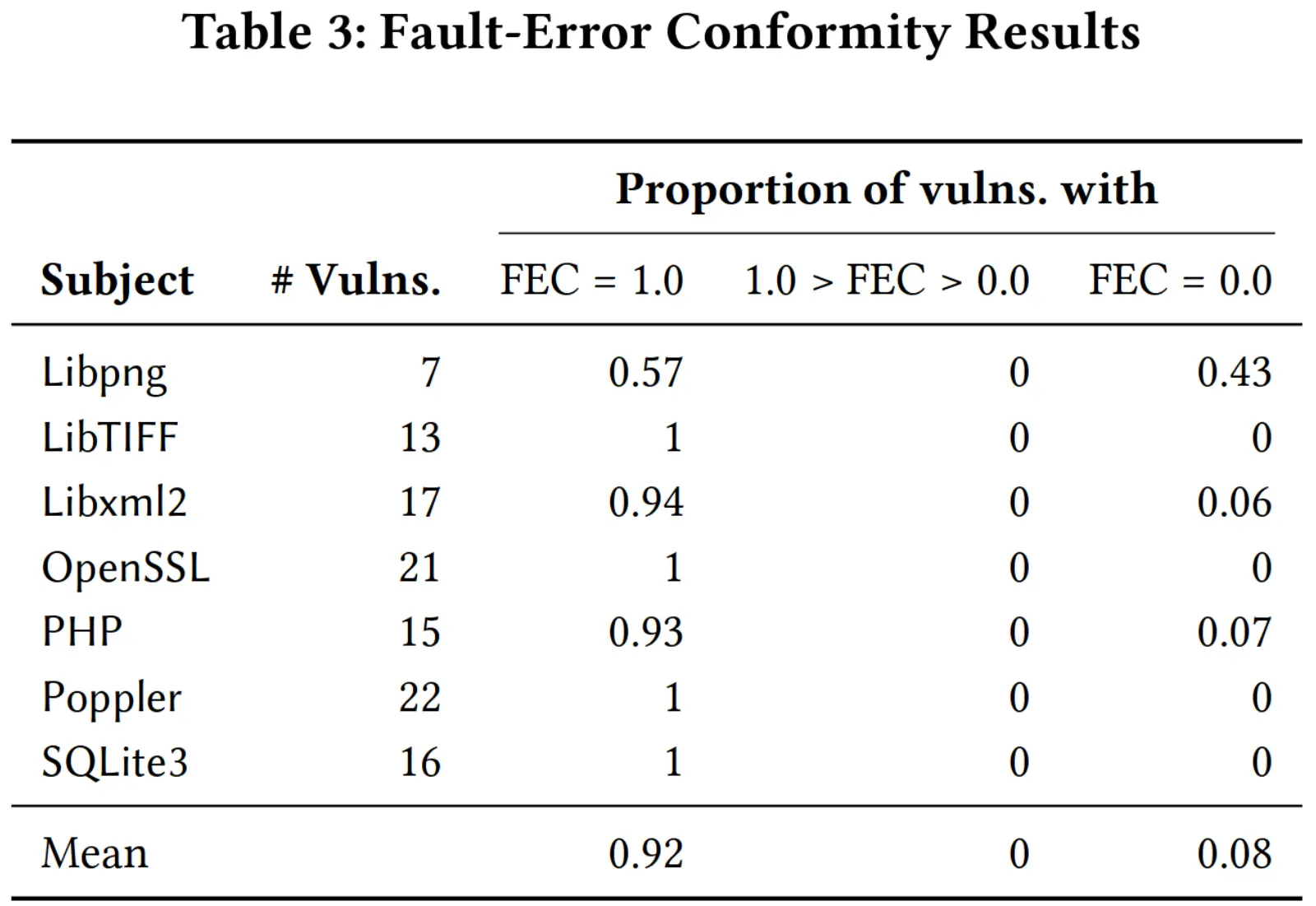
可以看到所有漏洞的 FEC 非 1 即 0,可能是因为本来多数漏洞就只有一处函数会显现 error,所以若 fault 与 error 位置相同即为 1,否则即为 0。
表格中看出不同应用各个漏洞的 FEC 基本都为 1,这说明对于多数漏洞 fault 和 error 都出现在相同的函数,所以设置 function-level 的粒度是合理的。
指标场景
本文设置了 Vuln. Detection Ratio 和 Marked Function Ratio 这两个指标:前者是检测到的漏洞与所有漏洞的数量之比,即召回率;后者是被标记的函数与所有函数的数量之比,可用来估算误报的程度。
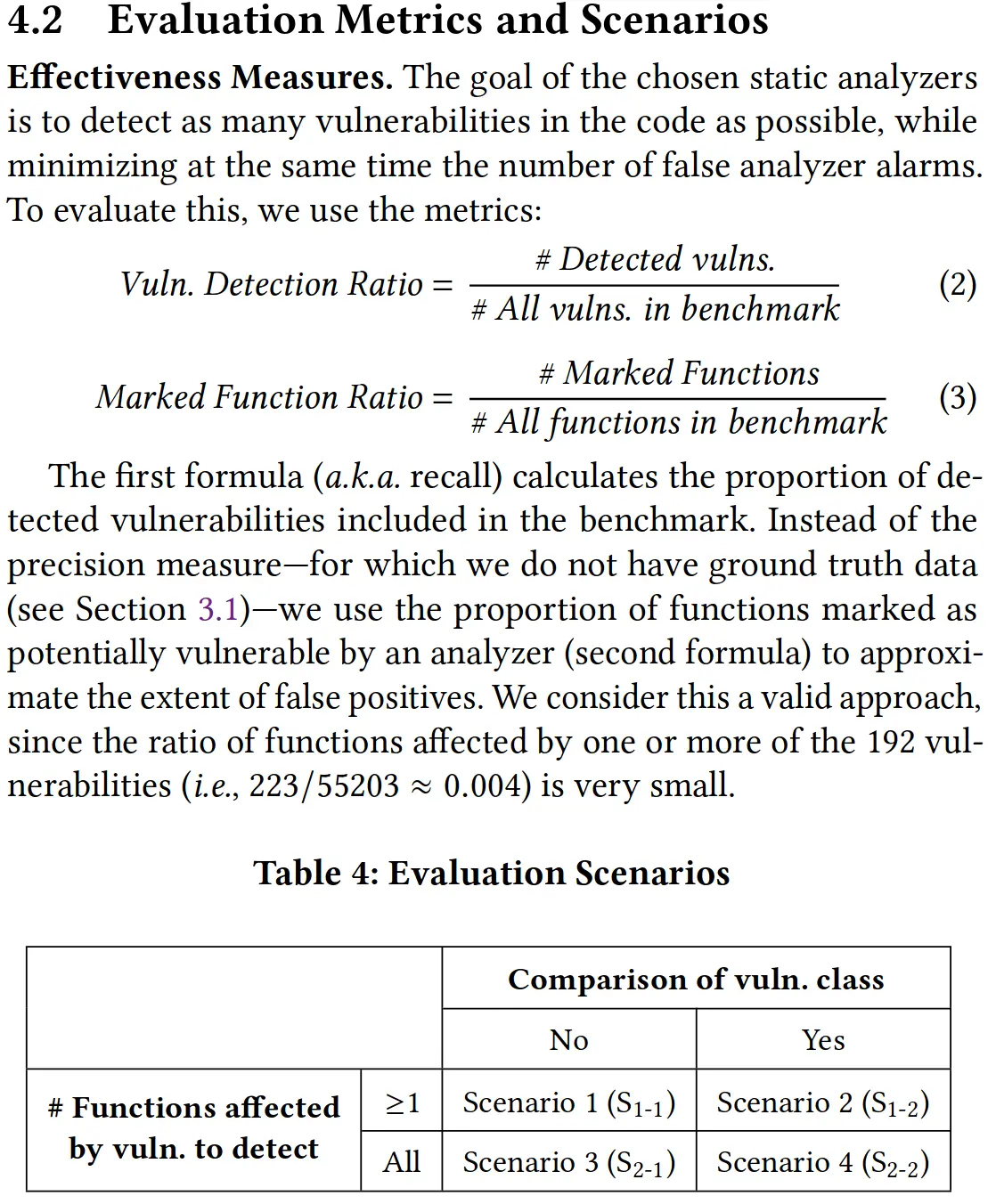
本文受 Thung 等人工作的启发,设置了四个不同的评估场景(scenario)来评判漏洞是否被检测成功,即是否需要比较漏洞种类确保符合,是否要检测出漏洞影响的所有函数,这样能调整松紧程度,从不同的角度检验静态分析器的效果。
实验结果
RQ.1: Static Analyzer Effectiveness
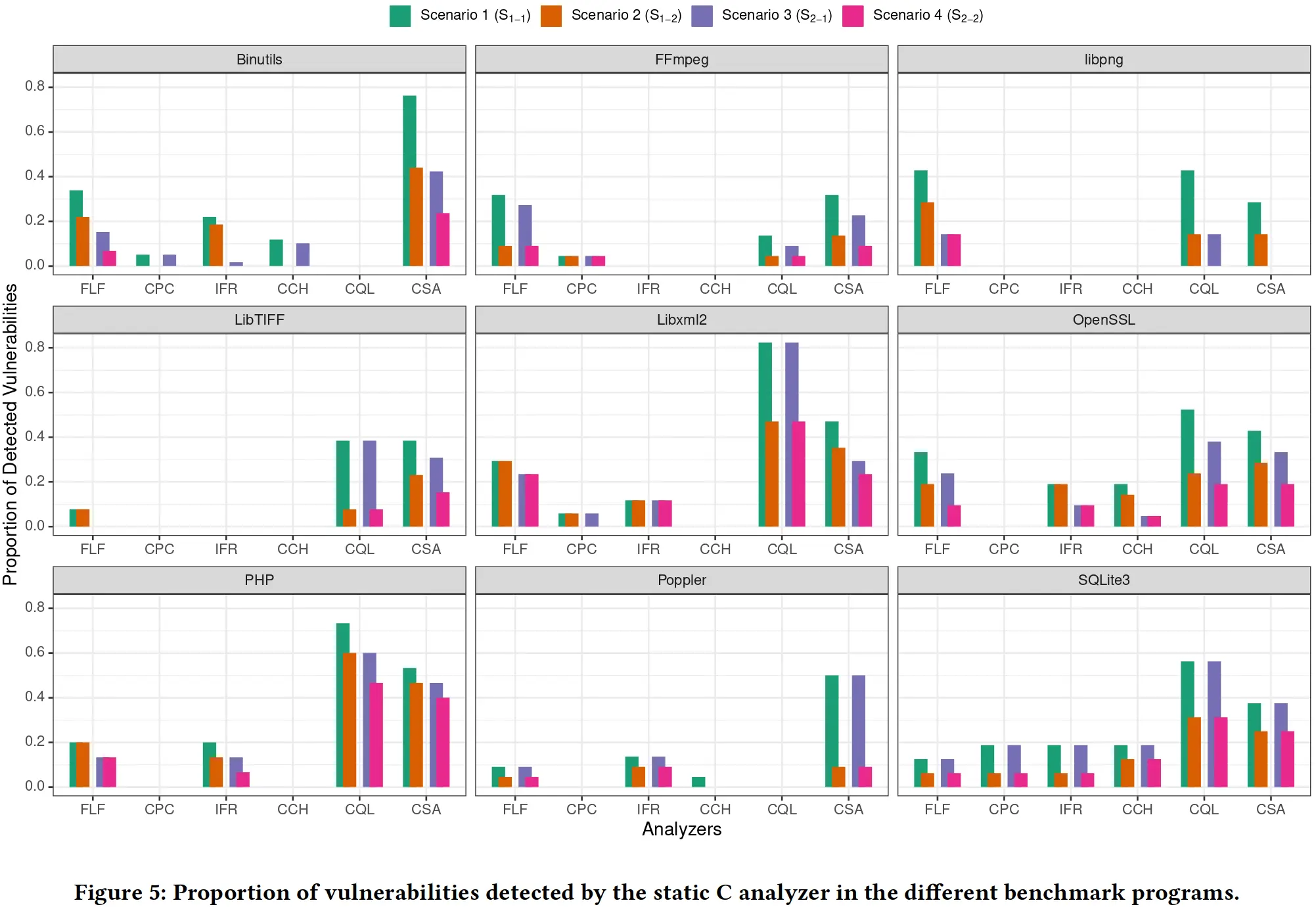
从被测程序的角度看,Poppler, FFmpeg, 和 Libpng 的漏洞检出率很低,作者分析了可能的原因:Poppler 是的被测程序中唯一一个用 C++ 编写的,尽管本文所测得静态分析器都支持 C/C++,但主要关注的还是 C,对 C++ 只有最基本的支持;FFmpeg 是被测程序中最大的,足有四十余万行代码,很可能触发了静态分析器所能分析的深度上限;Libpng 则是 Table 3 中 FEC 相对最低的,其 error 和 fault 位置的差异可能导致了静态分析的低检出率。
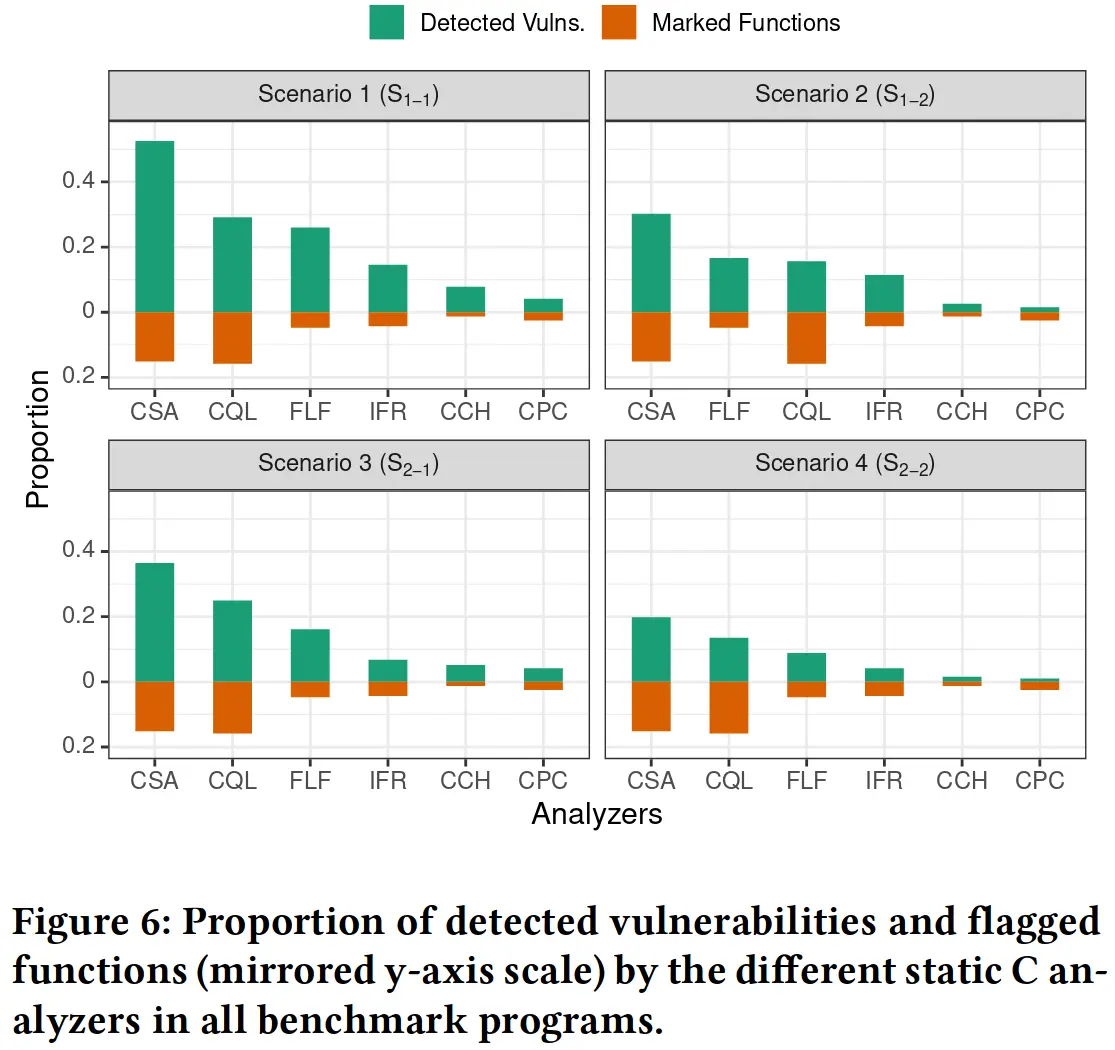
从分析工具的角度看,CommSCA, CodeQL 和 Flawfinder 表现最佳,Cppcheck, CodeChecker 和 Infer 表现最差,但即使是效果最好的 CommSCA 能检测出的漏洞也几乎不过半数。
RQ.2: Effectiveness Increase by Analyzer Combinations
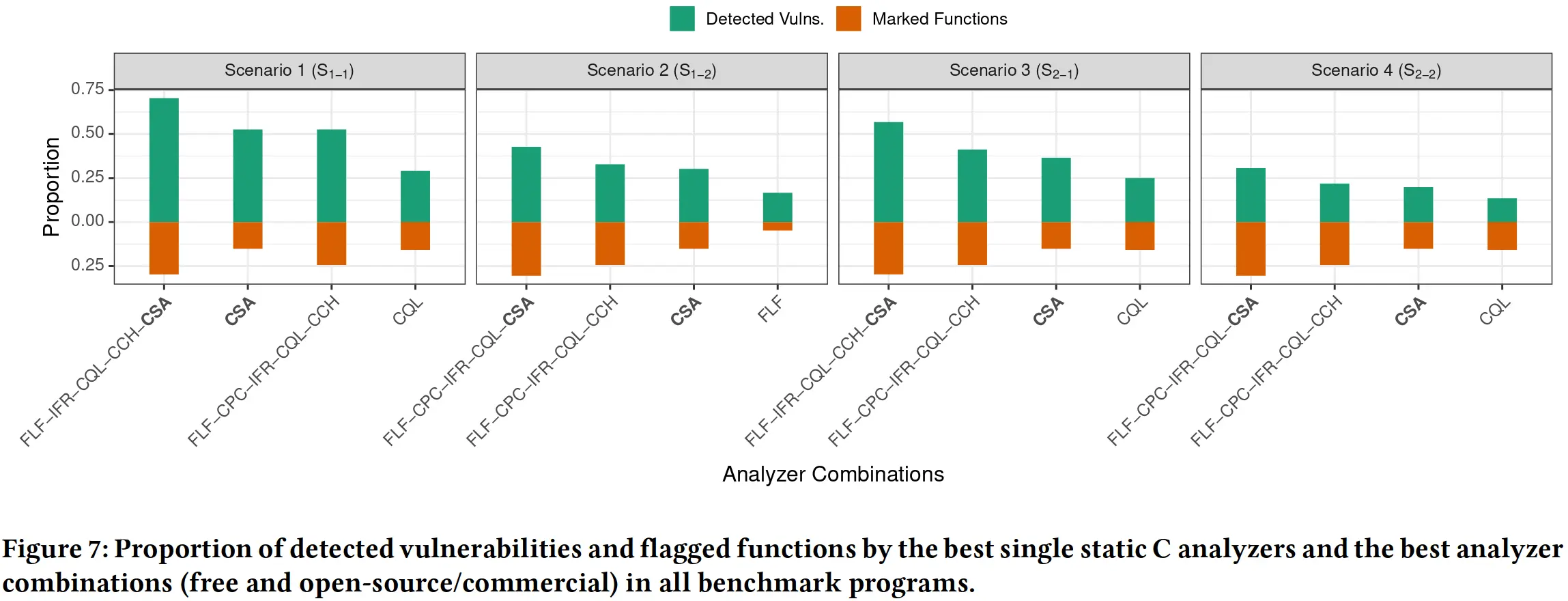
在不同场景下对多种静态分析工具进行组合搭配,在达到高检测率的同时尽可能使用更少的静态分析工具,结果表明最优的搭配一般能提升两三成的检测率,但同时会增加 15% 的误报可能,而且仍然有大概一半的漏洞无法被检出。
RQ.3: Best vs. Worst Detected Vulnerabilitiess
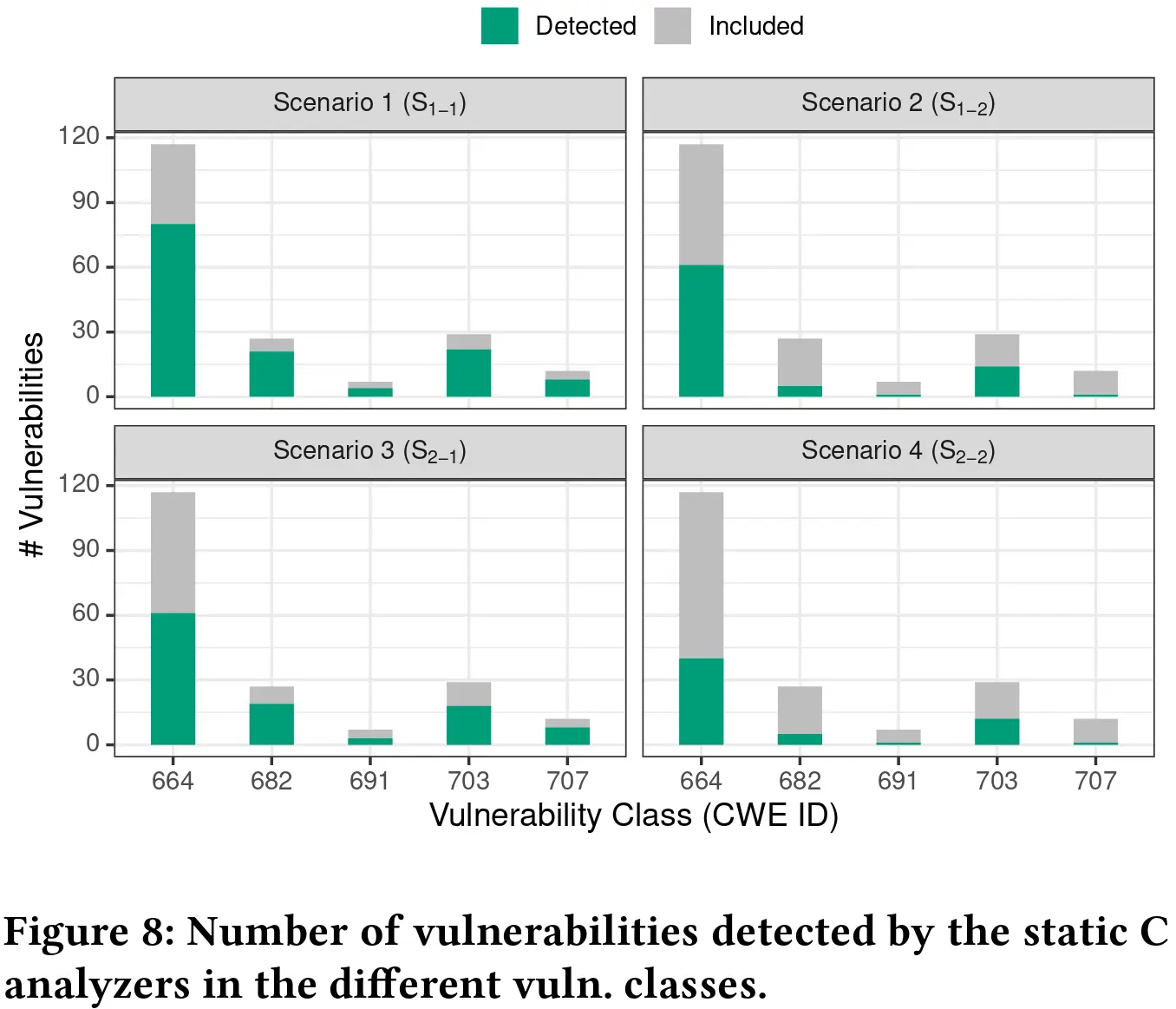
实验结果表明 CWE-664(资源生命周期控制不当)和 CWE-703(异常条件检查或处理不当) 比 CWE-{682,707,691} 更容易被静态分析,表现最差的两类 CWE 恰好就是 Table 2 中被静态分析器支持最少的那两类,而即使是表现最好的的 CWE-{664,703} 也有近半未被静态分析检出。
总结展望
作者称本文是未来对静态分析检测漏洞进行研究的基础,之后计划分析如此多漏洞无法被检测的深层的原因,以找到改进静态分析工具的方法并理解这类工具的普遍限制。
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。