Rust China Conf 2022 快速复盘

文章目录
第二届中国 Rust 开发者大会(Rust China Conf)原本该于 2021 年底在上海西岸智塔举办,可惜由于疫情延期到了今年,以全线上的方式开展,为时一天,上午是主会场,下午是多个分会场及 workshop 同时进行。会议内容之后会有官方的录播和回顾,本文只是对自己所参与两个会场的内容做简要整理,以让读者能够快速捕捉感兴趣的话题。
主会场
9:00 -12:00,包括四个专题分享和圆桌论坛
Rustdoc:你可以用它做什么,以及它的未来
Guillaume Gomez,华为工程师,Rustdoc Team Leader
介绍了 rustdoc 的功能特性和一些高级用法,由于时差原因没有 Q&A 环节,详细内容请见官方回放。
Rust 计算加速技术解读及高性能代码重构实践
李原,华为工程师
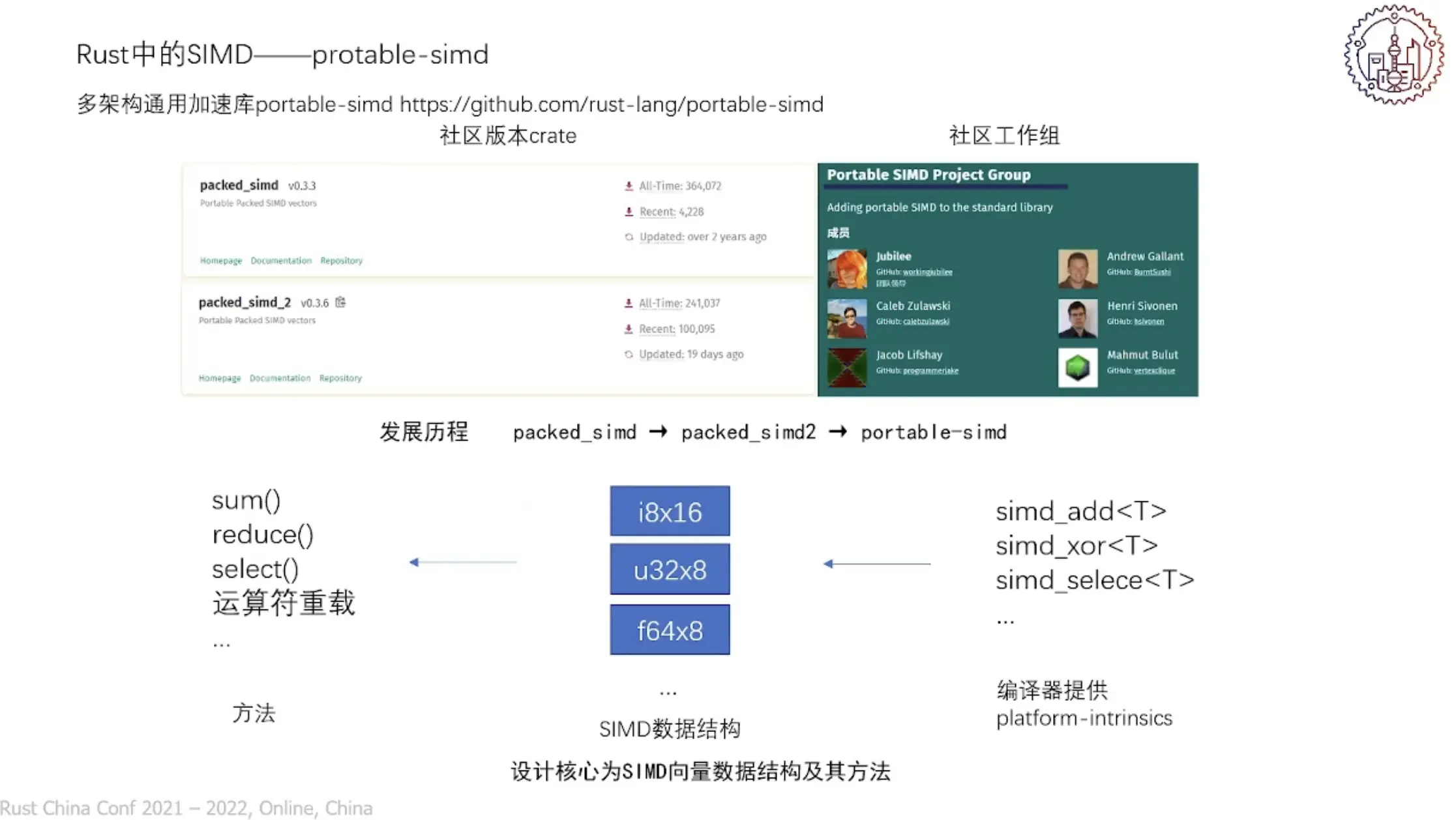
SIMD 是提高程序计算性能的重要方式,Rust 中的 SIMD 架构设计如下图:

具体实现有 stdarch 和 portable-simd,还介绍了其他计算加速技术,并举例说明了 SIMD 重构中的关键点定位和方法实践,详细内容可见官方回放。

从零开始实现Rust Fuzzer
陈鹏,腾讯安全大数据实验室安全研究员
陈鹏老师在 IEEE S&P 2018 上发表了 Angora: Efficient Fuzzing by Principled Search,用他幻灯片中的话说「可能是第一个用 Rust 实现的开源 Fuzzer」,注意这里指的是 Rust 来生成输入,对 Rust 代码进行测试是另一类工作。

好的 Fuzzer 要能生成高质量的输入,最原始的输入可从无状态的分布中获得,但为了达到更好的效果需要借助覆盖反馈和 type aware 生成有状态的分布,幻灯片中结合 Rust 实例代码讲解了生成和变异行为的实现。



除了生成高质量输入,Fuzzer 在执行时还需要考虑捕获异常,比如 Panic, Abort 和 Unsafe,并保留上下文以复现异常。

总之 Rust 能帮助开发者抽象输入生成,编写高效执行的 Fuzzer 并尽量避免 Fuzzer 自身的漏洞,其提供的 trait 系统也能让 Fuzzer 更加开箱即用,避免引入额外的代码和人工成本。
复杂 Rust 开源项目的维护
Robert Yan, Near Proctol 工程师
主讲人维护着代码行数超过 17 万的开源项目 NEAR,2021年开发者活跃度增长了四倍,本场分享可以说是维护 Rust 大型开源项目的经验心得,其中一些建议并不局限于 Rust 项目,所有开源项目都可以借鉴。
为项目维护一份简短的 architecture 文档可以让开发者快速上手,其中可包括:
- 鸟瞰图,描绘整个项目的结构
- 代码地图(Code Map),简洁地描述主要模块之间的关系,列出文件名即可而无需维护链接,显式地指出架构不变量(architectural invariants)


Rust 的包管理器 Cargo 对于小项目来说有很好的默认值,但对于有一定规模的项目来说并没有严格的规范,较为灵活,对于10万-100万行的项目,更推荐扁平结构而不是树形层级。

Rust 项目的构建时间普遍较长,这不止耗费机器资源,还会让开发者因等待编译而进行上下文切换,付出精力成本,也影响对项目的第一印象。而优化构建速度并不遵循二八定律,当编译时间长到一定程度后,并不是修改关键少数几行就能够大大加快编译速度的。
解决构建问题的银弹只有持续优化,平时就关注 CI 的构建时间,尽可能限制在 10 分钟内。在构建时可使用 --timings 选项分析哪些项目影响编译用时,阅读 Cargo.lock 观察是否有不必要依赖。
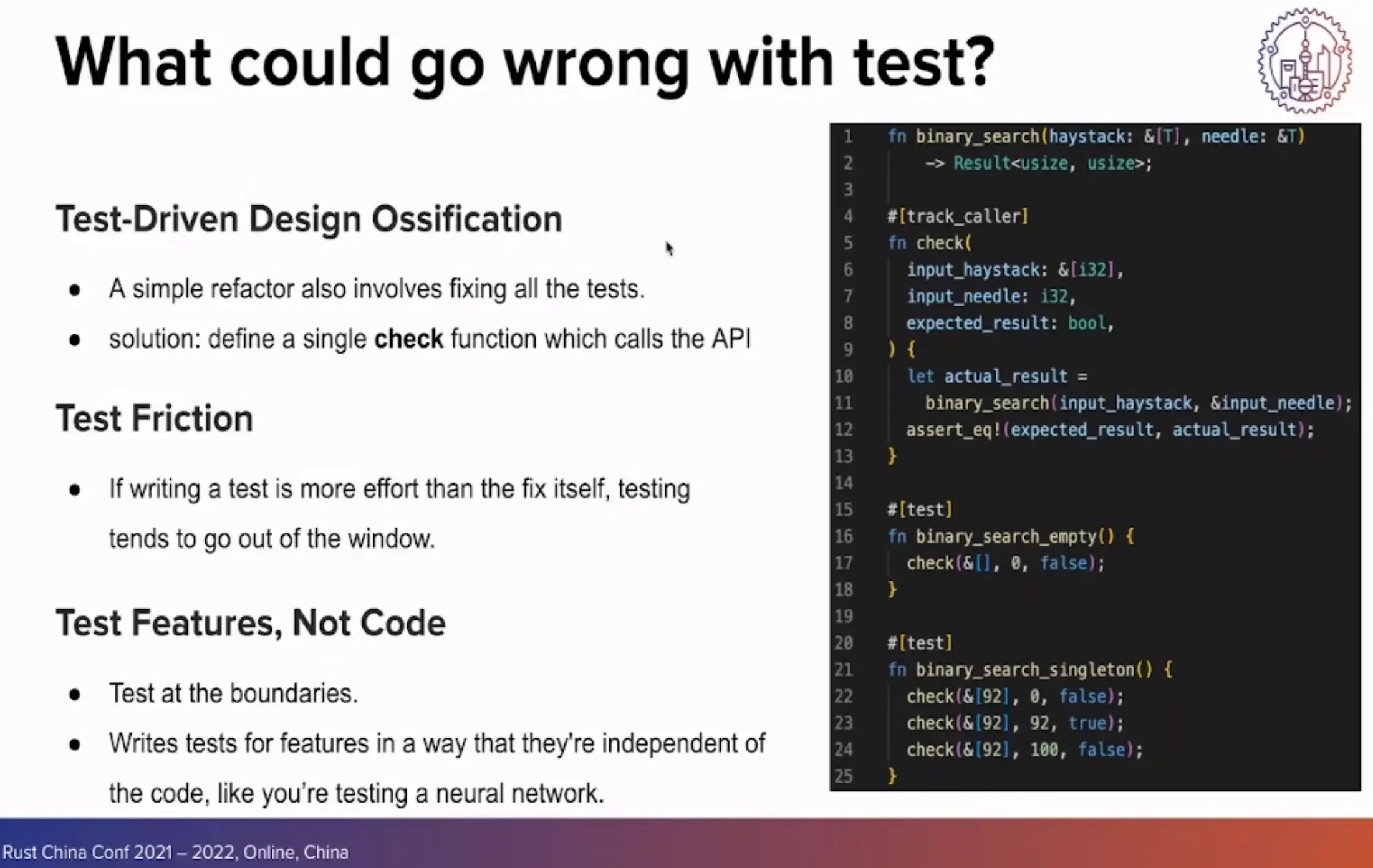

在编写测试代码时也要注意避免一些误区,让测试的基础设施具有可扩展性,详细内容可见官方回放。
分会场:Rust 语言研究与应用
这个分会场虽然围绕 Rust 语言,但说是安全专场也没问题,从代码混淆,模糊测试,再到编码规范,可以看成是安全开发流程中不断左移的三个阶段。
基于LLVM Rust代码混淆设计与实现
赵禅,蚂蚁集团基础安全部安全专家
C/C++ 开发的程序经常会使用代码混淆增大逆向难度,而随着 Rust 被越来越多的人使用,对 Rust 代码进行混淆也很有必要。Rust 大量使用 LLVM 作为其编译链工具,而现有的混淆工具大多都是作为 LLVM Pass 来提供混淆功能,其中最著名的便是 OLLVM,但其基于 LLVM 4.0 进行开发,与 Rust 不兼容,赵老师及其团队便自行设计实现了基于 LLVM 的 Rust 代码混淆系统。
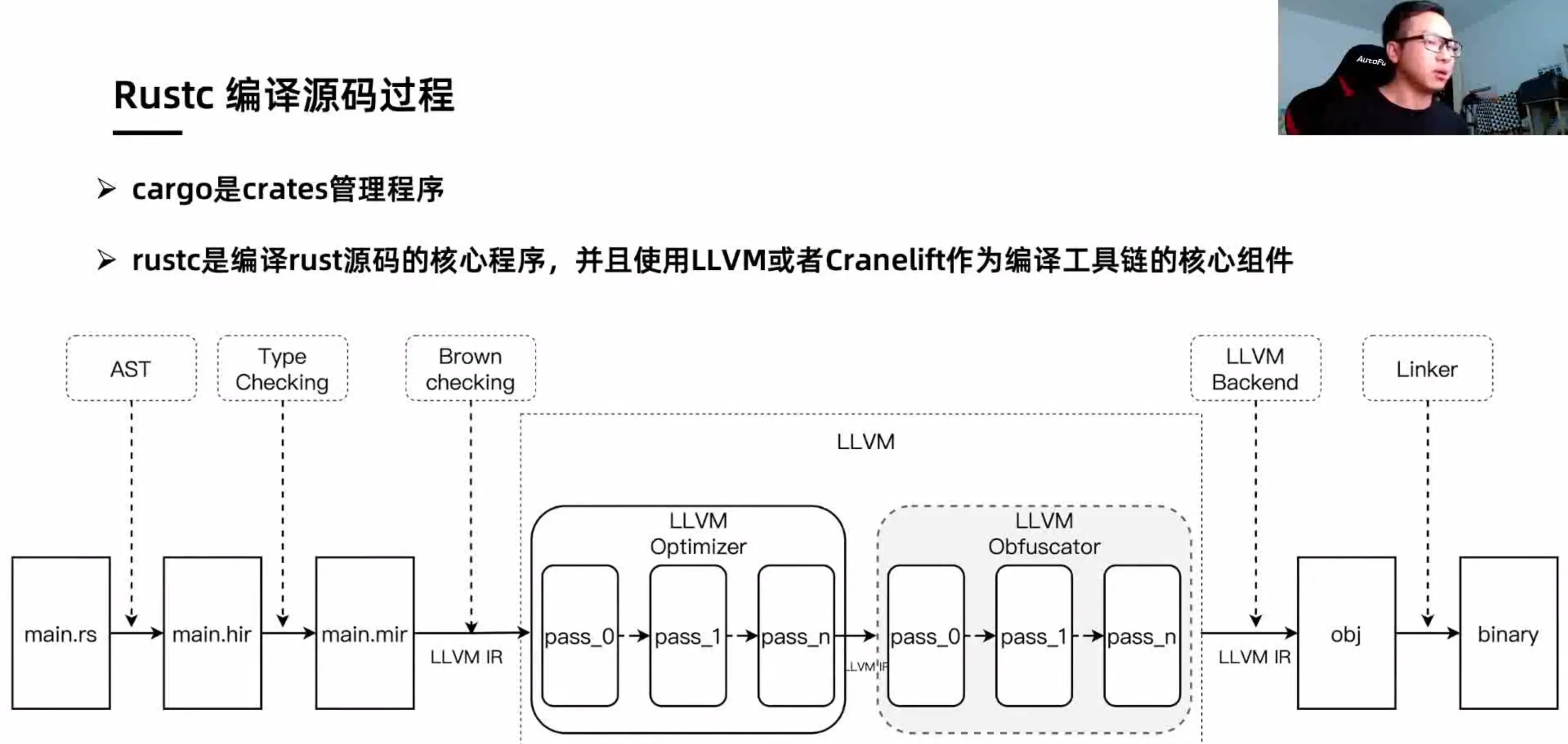
赵老师首先回顾了 LLVM 基本架构和 rustc 编译源码过程,介绍了虚假控制流和控制流平坦化这两种常见的混淆技术,并以 Web Assembly 代码混淆为例进行讲解。
 为了评估混淆系统的可靠性,在 RustCrypto 等库上开启全局混淆进行测试,发现并解决了一些兼容性问题,还给出了两个具体案例分析。
为了评估混淆系统的可靠性,在 RustCrypto 等库上开启全局混淆进行测试,发现并解决了一些兼容性问题,还给出了两个具体案例分析。
混淆对性能和生成文件的体积也会有一定影响,使用 MD5 操作进行评估,在不同混淆级别下的执行速度做了曲线图对比,详情见官方回放。
Rust API可靠性分析与验证
姜剑峰,蚂蚁集团高级工程师
Rust 语言结合静态检查与动态检查来实现内存安全,但语言本身提供的这些机制并不足以保证 API 的可靠性:

而常见的可靠性分析方法也都有其局限:

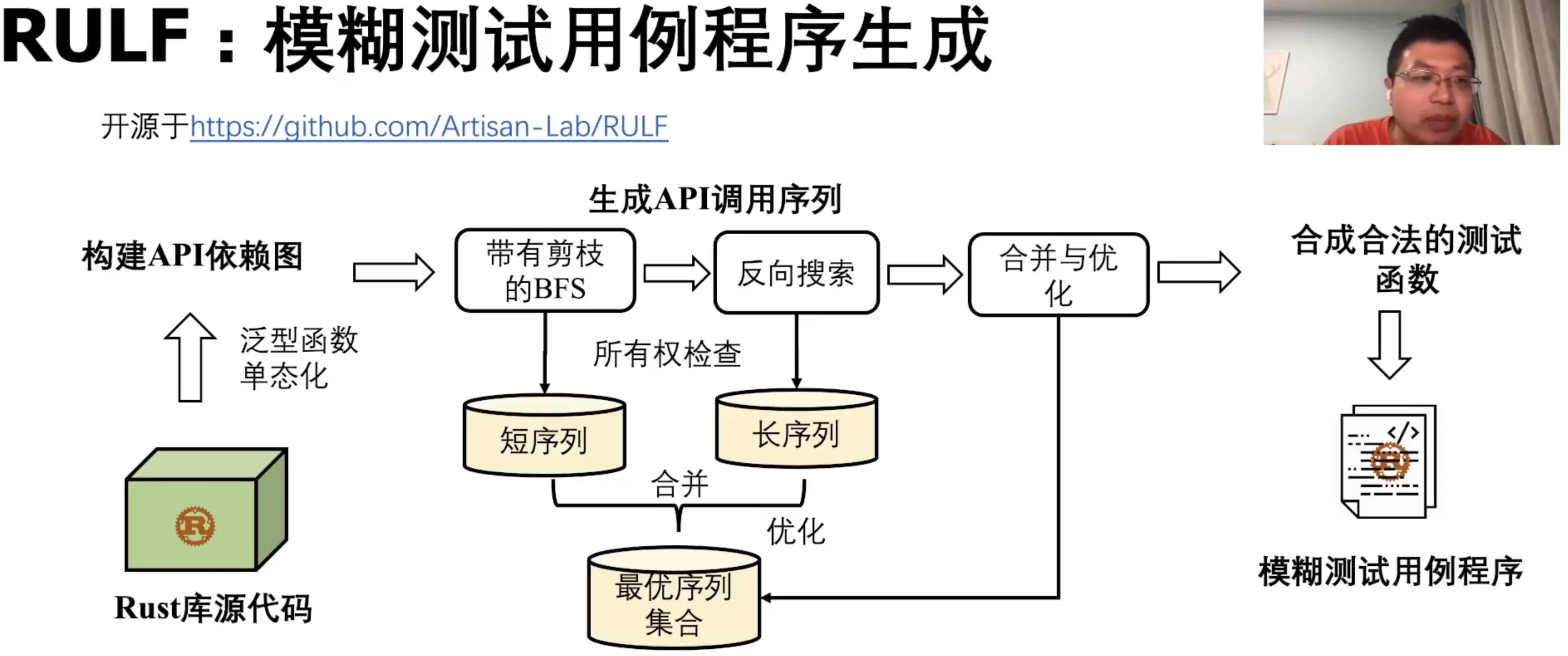
其中模糊测试技术已得到了较普遍的应用,上午的主会场中陈鹏老师就分享了如何用 Rust 从零开始实现 Fuzzer,而姜老师在复旦大学 Artisan-Lab 读研期间发表于 ASE 2021 的论文 RULF: Rust Library Fuzzing via API Dependency Graph Traversal 则是通过合成 API 调用代码来测试 Rust Library,值得一提的是这个工作基于 rustdoc 来提取 API 的签名信息,也算是主会场第一个分享「Rustdoc:你可以用它做什么」的真实案例,详情可见论文或官方回放。
你为什么需要「Rust 编码规范」
张汉东,独立企业咨询师
作为国内知名的 Rust 布道者,张汉东老师致力于推广统一的 Rust 编码规范,目前《Rust 编码规范》中文版 V 1.0 Beta 版已经发布试行,希望能够翻译推广到国外,详情可见官方回放。
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。