GSoC 2022 - Qiling Binary Emulation Meet R2 Static Analysis

文章目录
Hello. I’m chinggg, a participant of GSoC 2022 with Qiling. For the past few months, I’ve been working on bridging Qiling with Radare2 (also known as r2) to enhance binary emulation with static analysis.
Motivation
As a binary emulation framework, Qiling has done a nice job in emulation. But Qiling has limited ability to analyze binaries, users have to rely on other tools for useful information like function addresses then hardcode them, which is inconvenient.
My entire project aims to bridge Qiling with other static analysis software, thus providing users with binary information like symbols and high-level concepts like function, basic block and control flow graph. The robustness and usability of the project should also be improved to make everything tidy, which may involve some refactoring.
Showcase: De-obfuscation plugin against OLLVM control-flow flattening
When analyzing malware, it is common to see programs protected by code obfuscation. Obfuscator-LLVM may be the most widely used obfuscation tool for C/C++ programs, which implemented obfuscation like control flow flatenning.
We will not explain in details how OLLVM works because it is already very well explained in its wiki. To summarize, it flatten the original control flow using a big while-switch loop with many cases to hide real logic.
Qiling already has an IDA plugin that can recover OLLVM-protected program against control-flow flattening. With a click of mouse, users can identify real and fake blocks then patch the program. However, not everyone is willing to use IDA and sometimes Hex-Rays microcode APIs can be very confusing. So we implement a new de-flatten plugin that can be used in terminal using our new r2 extension.
We will use the same example code in Quarkslab’s blog to show how our de-flatten plugin works. The obfuscated binary will be uploaded to qilingframework/rootfs, you can also compile from source code following the instructions in the comments.
/* fla_test.c */
/* Build Instructions:
git clone git@github.com:heroims/obfuscator.git -b llvm-9.0
mkdir build-ollvm && cd build-ollvm
cmake -DCMAKE_BUILD_TYPE=Release -DLLVM_INCLUDE_TESTS=OFF -G Ninja ../obfuscator/
ninja
./bin/clang -m32 -mllvm -fla fla_test.c -o test_fla_argv
*/
#include <stdio.h>
#include <stdlib.h>
unsigned int target_function(unsigned int n)
{
unsigned int mod = n % 4;
unsigned int result = 0;
if (mod == 0) result = (n | 0xBAAAD0BF) * (2 ^ n);
else if (mod == 1) result = (n & 0xBAAAD0BF) * (3 + n);
else if (mod == 2) result = (n ^ 0xBAAAD0BF) * (4 | n);
else result = (n + 0xBAAAD0BF) * (5 & n);
return result;
}
int main(int argc, char **argv) {
int n;
if (argc < 2) {
n = 0;
} else {
n = atoi(argv[1]);
}
int val = target_function(n);
printf("%d\n", val);
return 0;
}
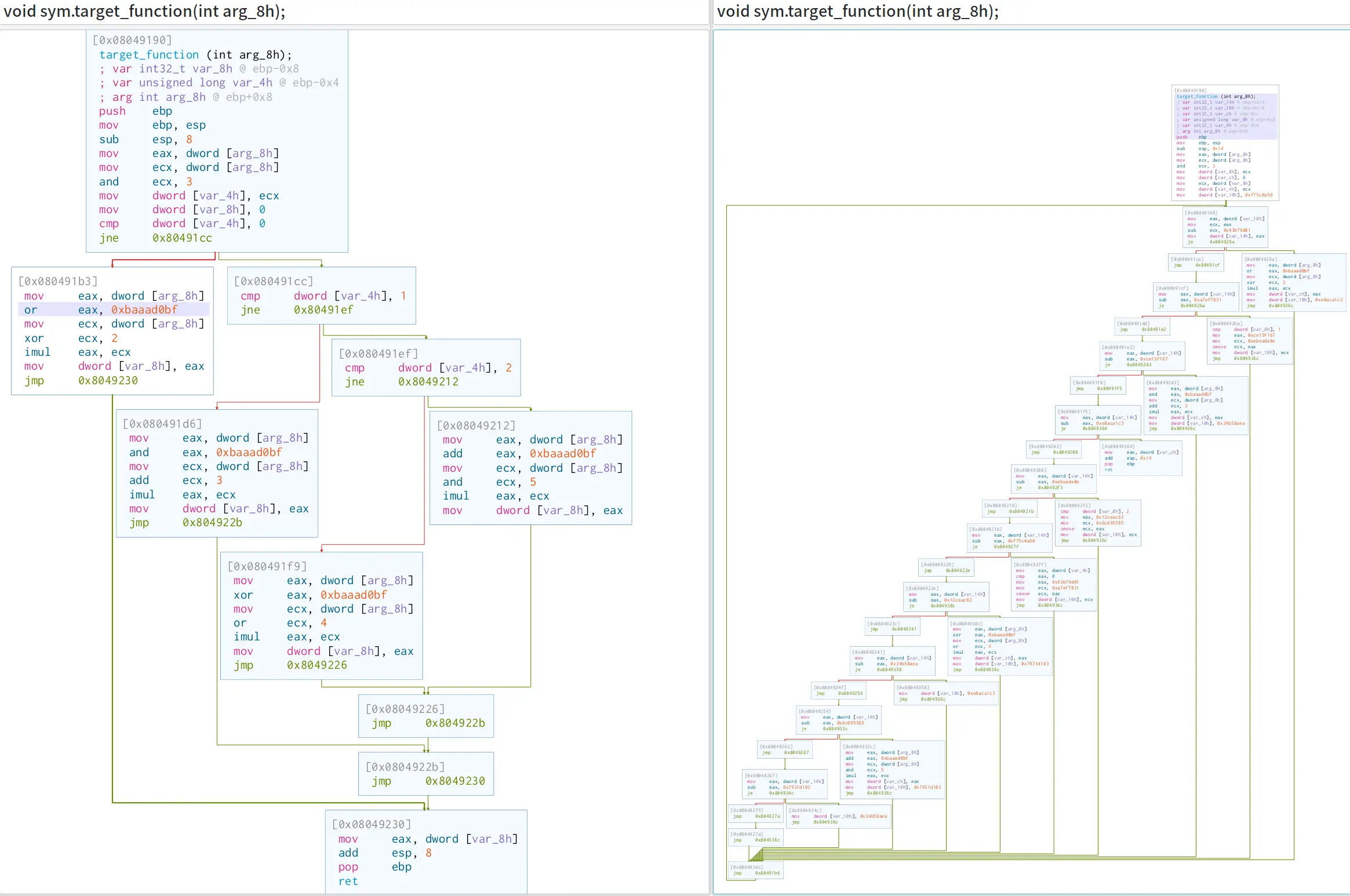
Using Cutter, we can see that the original control flow graph of obfuscated program (right) looks very different from the original progam (left).
Given a function obfuscated by control flow flattening, its should contain basic blocks that can be classified into different types as below.
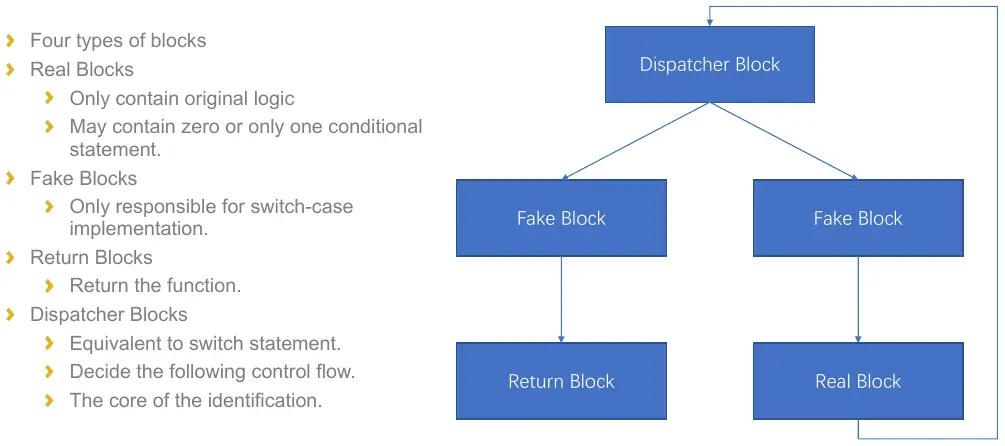
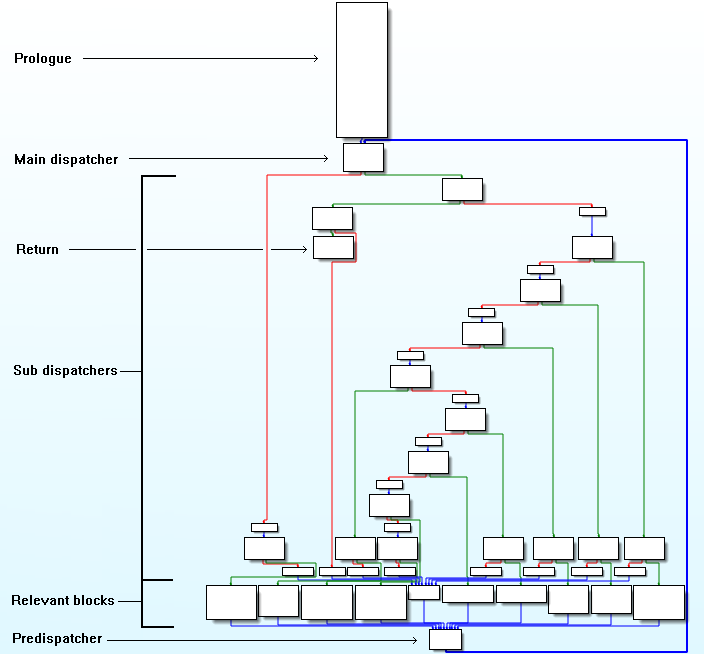
The predispatcher can be easily discovered since it is the block with max in-degree in the control flow graph. Then dispatcher is just the block that predispatcher should jump to. The return blocks are those who terminate without having a jump destination. The real blocks contain more than one instructions and have successor is the dispatcher.
Now we have obtained different types of blocks using very basic static analysis, so what’s the role of Qiling here? Emulation makes the de-obfuscation much more robust and general and can work under less assumptions, like the optimization level, the complexity of original control flow or even the version of the Hexrays decompiler because we try to avoid matching fixed microcode patterns.
In order to find real control flow, we start emulation from the beginning of every real block with a guide_hook, which will stop emulation if reaching another real block or return block, thus getting paths from real blocks to real blocks. More work should be done for blocks containing conditional branch instruction like cmov, since they have multiple potential states which may lead to different paths. So we emulate these blocks twice and force set different register values to cover both conditions and hopefully get two destinations.
Currently I the translate the semantic of conditional branches instruction by manually comparing the operand since I only consider cmov instruction in x86 binaries. But if we want to support more architecture, we need some kind of immediate representation that is platform independent. Luckily r2 can provide ESIL for each instruction, which describe the opcode semantics. Given ESIL of a conditional branch instruction, we want to get exactly the source and destination under different branches, though I have no idea which instructions we may meet specifically in other architectures like ARM.
To test the de-flatten functionality, just run the following script.
from qiling.extensions.r2 import R2Qiling
ql = R2Qiling(['rootfs/x86_linux/bin/test_fla_argv', '1'], 'rootfs/x86_linux', verbose=QL_VERBOSE.DEFAULT)
r2 = ql.r2
# now we can use r2 parsed symbol name instead of address
fcn = r2.get_fcn_at(r2.where('target_function'))
print(fcn)
r2.deflat(fcn)
ql.run()
r2.shell()

Introduce R2 extension and human-friendly disassembler
As originally posted in the GitHub discussion, we have multiple choices like IDA Pro, Ghidra, RetDec and BinaryNinja. But we finally choose radare2 since it’s open source and @lazymio has wrote a self-contained Python binding r2libr for it.
Radare2 is a command-line reverse engineering framework with a shell-like UI, where users enter commands then get results. The result is always returned as string, but most commands can print in JSON format, which can be easily converted to Python dictionary. So Qiling can get the necessary information and store them as custom objects, on top of which more high level methods could be built.
For better maintainability, I use dataclass to organize JSON data got from r2 and make a useful base class.
class R2Data:
def __init__(self, **kwargs):
names = set([f.name for f in fields(self)])
for k, v in kwargs.items():
if k in names:
setattr(self, k, v)
def __str__(self):
kvs = []
for k, v in sorted(self.__dict__.items()):
if k.startswith("_") or not isinstance(v, (int, str)):
continue
v = hex(v) if isinstance(v, int) else v
kvs.append(f"{k}={v}")
return (f"{self.__class__.__name__}(" + ", ".join(kvs) + ")")
__repr__ = __str__
@cached_property
def start_ea(self):
return getattr(self, 'addr', None) or getattr(self, 'offset', None) or getattr(self, 'vaddr', None)
@cached_property
def end_ea(self):
size = getattr(self, 'size', None) or getattr(self, 'length', None)
if (self.start_ea or size) is None:
return None
return self.start_ea + size
def __contains__(self, target):
if isinstance(target, int):
return self.start_ea <= target < (self.end_ea or 1<<32)
else:
return self.start_ea <= target.start_ea and ((target.end_ea or target.start_ea) <= (self.end_ea or 1<<32))
So I can add r2 data structures as inherited classes with just a few lines of code:
@dataclass(unsafe_hash=True, init=False)
class Function(R2Data):
name: str
offset: int
size: int
signature: str
@dataclass(unsafe_hash=True, init=False)
class BasicBlock(R2Data):
addr: int
size: int
inputs: int
outputs: int
ninstr: int
jump: Optional[int] = None
fail: Optional[int] = None
@dataclass(unsafe_hash=True, init=False)
class Instruction(R2Data):
offset: int
size: int
opcode: str # raw opcode
disasm: str = '' # flag resolved opcode
bytes: bytes
type: str
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.bytes = bytes.fromhex(kwargs["bytes"])
def is_jcond(self):
return self.type in ("cjmp", "cmov")
After that, we can build the R2 class to create radare2 instance and using our familiar command line interface to get useful data about the binary.
class R2:
def __init__(self, ql: "Qiling", baseaddr=(1 << 64) - 1, loadaddr=0):
self.ql = ql
self.analyzed = False
self._r2c = libr.r_core.r_core_new()
def _cmd(self, cmd: str) -> str:
r = libr.r_core.r_core_cmd_str(
self._r2c, ctypes.create_string_buffer(cmd.encode("utf-8")))
return ctypes.string_at(r).decode('utf-8')
def _cmdj(self, cmd: str) -> Union[Dict, List[Dict]]:
return json.loads(self._cmd(cmd))
@cached_property
@aaa
def functions(self) -> Dict[str, Function]:
fcn_lst = self._cmdj("aflj")
return {dic['name']: Function(**dic) for dic in fcn_lst}
A nice feature of radare2 is the flag system, which can associate a name with a given offset in a file. Symbols, sections and analyzed functions are already flagged by default. So we can design functions to convert between address and name + offset easily:
def at(self, addr: int, parse=False) -> Union[str, Tuple[str, int]]:
'''Given an address, return [name, offset] or "name + offset"'''
name = self._cmd(f'fd {addr}').strip()
if parse:
try:
name, offset = name.split(' + ')
offset = int(offset)
except ValueError: # split fail when offset=0
offset = 0
return name, offset
return name
def where(self, name: str, offset: int=0) -> int:
'''Given a name (+ offset), return its address (0 when not found)'''
if offset != 0: # name can already have offset, multiple + is allowd
name += f' + {offset}'
addr = self._cmd(f'?v {name}').strip() # 0x0 when name is not found
return int(addr, 16)
Now we have these APIs provided by r2, but what can be done to enhance Qiling? I think some improvements can be made to the existing disassembler to make it print human-friendly disassembly with addresses already resolved as flags just as what we see in r2. But keep in mind that r2 is now still an extension instead of part of Qiling itself, which means Qiling cannot keep a persistent r2 instance internally. So I made a hook-like disassembler function in r2 and monky patch the original disassembler to try it first.
def disassembler(self, ql: 'Qiling', addr: int, size: int, filt: Pattern[str]=None) -> int:
'''A human-friendly monkey patch of QlArchUtils.disassembler powered by r2, can be used for hook_code
:param ql: Qiling instance
:param addr: start address for disassembly
:param size: size in bytes
:param filt: regex pattern to filter instructions
:return: progress of dissembler, should be equal to size if success
'''
anibbles = ql.arch.bits // 4
progress = 0
for inst in self.dis_nbytes(addr, size):
if inst.type.lower() in ('invalid', 'ill'):
break # stop disasm
name, offset = self.at(inst.offset, parse=True)
if filt is None or filt.search(name):
ql.log.info(f'{inst.offset:0{anibbles}x} [{name:20s} + {offset:#08x}] {inst.bytes.hex(" "):20s} {inst.disasm}')
progress = inst.offset + inst.size - addr
if progress < size:
ql.arch.utils.disassembler(ql, addr + progress, size - progress)
return progress
# In qiling/arch/utils.py
if verbosity >= QL_VERBOSE.DISASM:
try: # monkey patch disassembler
from qiling.extensions.r2 import R2
r2 = R2(self.ql)
self._disasm_hook = self.ql.hook_code(r2.disassembler)
except (ImportError, ModuleNotFoundError):
self._disasm_hook = self.ql.hook_code(self.disassembler)
Share memory between Unicorn and Radare2
Although the r2 extension can provide some useful APIs for users, the integration is not complete since r2 was only used for parsing binary information statically. The r2 extension was unaware of the memory emulated in Qiling, so it fails under some circumstances (eg. ql.patch can modify the binary at any time or the binary can dynamically unpack itself during runtime)
Keeping the memory consistency between Qiling and radare2 is difficult, so instead of maintaining two independent memory content, reusing the memory in Qiling seems to be the solution.
Qiling inherit its emulation ability from Unicorn Engine, which provides APIs to map a new memory range and read from / write to it. Here we show three unicorn APIs in the form of Python bindings.
def mem_map(self, address: int, size: int, perms: int):
def mem_read(self, address: int, size: int) -> bytearray:
def mem_write(self, address: int, data: bytes):
Usually the unicorn memory is allocated inside a black box, so it is impossible to use the memory directly in Python code. Luckily, unicorn also provides an API to map a range of memory from a raw host memory address, which allows a pointer/reference to be passed.
def mem_map_ptr(self, address: int, size: int, perms: int, ptr: int):
Based on mem_map_ptr, I design a new API for QlMemoryManager to map the reference of a bytearray to unicorn.
def map_ptr(self, addr: int, size: int, perms: int = UC_PROT_ALL, buf: Optional[bytearray] = None) -> bytearray:
It utilizes the ctypes API from_buffer to create data reference for bytearray that can be passed to uc.mem_map_ptr. If buf is not provided, a new bytearray of size will be created and returned. So we can modify the implementation of QlMemoryManager.map to internally use map_ptr without changing the interface.
However, memory management is not easy, especially in Python. We must be very careful about the lifetime of variables and ensure the reference is valid then destroy them when the memory is released.
QlMemoryManager maintain memory map information (map_info) as tuples like (start, end, perm, label, is_mmio), I add bytearray to the end of the tuple to store the data so it will not be collected when the local variable is out of scope. Another thing that bothered me a lot is that the buffer created by from_buffer should also be kept alive, so I add a dictionary cmap to map from the start address to the ctypes data.
Finally we get to methods like below, map works as before and calls add_mapinfo while map_ptr is more like a wrapper of uc.mem_map_ptr which does not affect map_info.
def map(self, addr: int, size: int, perms: int = UC_PROT_ALL, info: Optional[str] = None, ptr: Optional[bytearray] = None):
buf = self.map_ptr(addr, size, perms, ptr)
self.add_mapinfo(addr, addr + size, perms, info or '[mapped]', is_mmio=False, data=buf)
def map_ptr(self, addr: int, size: int, perms: int = UC_PROT_ALL, buf: Optional[bytearray] = None) -> bytearray:
buf = buf or bytearray(size)
buf_type = ctypes.c_ubyte * size
cdata = buf_type.from_buffer(buf)
self.cmap[addr] = cdata
self.ql.uc.mem_map_ptr(addr, size, perms, cdata)
return buf
Things get even harder when we want to unmap a range of memory. Though the function only contain two lines of code, it will call del_mapinfo, which now not only deal with address ranges, but also the bytearray data.
def unmap(self, addr: int, size: int) -> None:
self.del_mapinfo(addr, addr + size)
self.ql.uc.mem_unmap(addr, size)
Since memory is allocated in a linear address space, we can subtract any memory range from existing map. In the past we only have to iterate the existing map_info and create new tuples when the address range overlaps with the range that needs to be deleted. But now, the bytearray stored in map_info should be sliced with caution and we must call uc.mem_unmap and self.map_ptr for each newly created tuple to ensure the data is mapped in unicorn correctly.
def del_mapinfo(self, mem_s: int, mem_e: int):
"""Subtract a memory range from map, will destroy data and unmap uc mem in the range.
Args:
mem_s: memory range start
mem_e: memory range end
"""
tmp_map_info: MutableSequence[MapInfoEntry] = []
for s, e, p, info, mmio, data in self.map_info:
if e <= mem_s:
tmp_map_info.append((s, e, p, info, mmio, data))
continue
if s >= mem_e:
tmp_map_info.append((s, e, p, info, mmio, data))
continue
del self.cmap[s] # remove cdata reference starting at s
if s < mem_s:
self.ql.uc.mem_unmap(s, mem_s - s)
self.map_ptr(s, mem_s - s, p, data[:mem_s - s])
tmp_map_info.append((s, mem_s, p, info, mmio, data[:mem_s - s]))
if s == mem_s:
pass
if e > mem_e:
self.ql.uc.mem_unmap(mem_e, e - mem_e)
self.map_ptr(mem_e, e - mem_e, p, data[mem_e - e:])
tmp_map_info.append((mem_e, e, p, info, mmio, data[mem_e - e:]))
if e == mem_e:
pass
del data[mem_s - s:mem_e - s]
self.map_info = tmp_map_info
People may assume map_info is changed only in functions like map and unmap which will also call the corresponding unicorn API, but it is possible to directly call change_mapinfo in the implementation of syscall_mmap. So it’s really tricky to debug memory related errors, I even make an utility function as a hook to assert the memory consistency on each instruction, which may help me find the root cause (i.e. address where memory inconsistency starts):
def assert_mem_equal(ql: 'Qiling'):
map_info = ql.mem.map_info
mem_regions = list(ql.uc.mem_regions())
assert len(map_info) == len(mem_regions), f'len: map_info={len(map_info)} != mem_regions={len(mem_regions)}'
for i, mem_region in enumerate(mem_regions):
s, e, p, label, _, data = map_info[i]
if (s, e - 1, p) != mem_region:
ql.log.error('map_info:')
print('\n'.join(ql.mem.get_formatted_mapinfo()))
ql.log.error('uc.mem_regions:')
print('\n'.join(f'{s:010x} - {e:010x} {uc2perm(p)}' for (s, e, p) in mem_regions))
raise AssertionError(f'(start, end, perm): map_info={(s, e - 1, p)} != mem_region={mem_region}')
uc_mem = ql.mem.read(mem_region[0], mem_region[1] - mem_region[0] + 1)
assert len(data) == len(uc_mem), f'len of {i} mem: map_info={len(data)} != mem_region={len(uc_mem)}'
if data != uc_mem:
Path('/tmp/uc_mem.bin').write_bytes(uc_mem)
Path('/tmp/map_info.bin').write_bytes(data)
raise AssertionError(f'Memory region {i} {s:#x} - {e:#x} != map_info[{i}] {label}')
After lots of struggle, memory in Qiling can be accessed directly, so we can refactor r2 extension to set up using the memory map in Qiling instead of file path or binary data. We made it using RBuffer, which is just yet another undocumented feature provided by r2.
def _rbuf_map(self, cbuf: ctypes.Array[ctypes.c_ubyte], perm: int = UC_PROT_ALL, addr: int = 0, delta: int = 0):
rbuf = libr.r_buf_new_with_pointers(cbuf, len(cbuf), False) # last arg `steal` = False
rbuf = ctypes.cast(rbuf, ctypes.POINTER(libr.r_io.struct_r_buf_t))
desc = libr.r_io_open_buffer(self._r2i, rbuf, UC_PROT_ALL, 0) # last arg `mode` is always 0 in r2 code
libr.r_io.r_io_map_add(self._r2i, desc.contents.fd, desc.contents.perm, delta, addr, len(cbuf))
def _setup_mem(self, ql: 'Qiling'):
if not hasattr(ql, '_mem'):
return
for start, _end, perms, _label, _mmio, _buf in ql.mem.map_info:
cbuf = ql.mem.cmap[start]
self._rbuf_map(cbuf, perms, start)
# set architecture and bits for r2 asm
arch = self._qlarch2r(ql.arch.type)
self._cmd(f"e,asm.arch={arch},asm.bits={ql.arch.bits}")
self._cmd("oba") # load bininfo and update flags
Reflections and Future Work
Introducing new feature for a project is usually welcomed, while replacing the old implementation in the core part with new one requires agreement from all maintainers, which may involve much effort on debating. Adding new components without cautious consideration will make the code hard to maintain in the further.
Both my mentor and I did not expect the obstacles on memory management that blocked our progress for weeks. Now there are still two memory related bugs #1136 and #1137, which already existed even before I started contributing. Maybe further refactoring on QlMemoryManager is needed in the future.
Now the ability of r2 has not been fully exploited yet, we expect more work can be done to support more file formats and more useful analysis.
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。