ML-Leaks: 针对机器学习模型的成员推理攻击

文章目录
前言
本文将对 NDSS (Network and Distributed System Security Symposium) 2019 获奖论文 ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models 进行解读。这篇论文的主要研究内容是针对机器学习模型的成员推理攻击(membership inference attack)以及对应的防御机制,其价值在于证明了经过改进后的成员推理攻击具有较低的成本和较强的可行性,从而构成更现实的威胁。
论文地址:https://www.ndss-symposium.org/wp-content/uploads/2019/02/ndss2019_03A-1_Salem_paper.pdf
源码地址:https://github.com/AhmedSalem2/ML-Leaks
论文作者:Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, Michael Backes
正文
研究背景
机器学习已经成为许多现实应用的核心,互联网巨头如 Google 和 Amazon 已经在推广机器学习即服务(MLaaS)的模式,用户可以上传自己的数据集,服务器返回给用户一个训练好的机器学习模型,通常是一个黑盒 API。尽管机器学习模型已得到广泛应用,但它在安全和隐私上却易受攻击,如模型逆向(model inversion)、对抗样本(adversarial examples)和模型提取(model extraction)。
本文关注的是成员推理攻击(membership inference attack),攻击者的意图是得知某个数据是否被用于训练机器学习模型,这种攻击可能引发严重的后果,比如一个机器学习模型在来自特定疾病患者的数据上训练,攻击者通过得知受害者的数据属于模型的训练集就能立刻推知其健康状况。
早在2017年,Shokri 等人第一次展示了针对机器学习模型的成员推理攻击,大致思路是使用多个攻击模型(attack models)来对目标模型(target model)的输出,即后验概率(posterior probabilities),进行成员推理。考虑到目标模型是一个黑盒 API,Shokri 等人构造了多个影子模型以模拟目标模型的行为并导出训练攻击模型所需的数据,即后验和真实(ground truth)的成员情况。
Shokri 等人的工作基于两个主要假设。首先,攻击者需要建立多个影子模型模型,每个模型与目标模型具有相同的结构,这可以通过使用与训练目标模型相同的 MLaaS 实现。第二,用于训练影子模型的数据集来自与目标模型的训练数据相同的分布,这一假设适用于对大部分攻击的评估。Shokir 等人也进一步提出了合成数据来放宽这一假设,但由于效率原因这种方法只能适用于包含二值特征的数据集。
这两个较强的假设减少了对机器学习模型进行成员推理攻击的攻击面,本文将逐步放宽这些假设,以表明更广泛适用的攻击场景是可能的,同时也提出了两种防御机制。
准备工作
本文主要关注分类问题,机器学习中的分类器就是一个函数,其将一个数据点(多维特征向量)映射成一个输出向量$\mathcal{M(X)=Y}$,$\mathcal{Y}$ 的长度等于类别的个数,大多数情况下 $\mathcal{Y}$ 可被解释成在所有类别上后验概率的集合, $\mathcal{Y}$ 中所有值的和为1。
而成员推理攻击的攻击模型可表示成如下函数 $\mathcal{A}:X_{Target},\mathcal{M,K}\rightarrow{0,1}$,其中 $X_{Target}$ 为目标数据点,$\mathcal{M}$ 为训练后的模型(称为目标模型),$\mathcal{K}$ 为攻击者的外部知识,结果为0表示目标数据点不是目标模型训练集 $\mathcal{D}_{Train}$ 的成员,为1则反之。
本文利用8个不同的数据集进行实验,其中6个与 Shokri 等人使用的数据相同,即MNIST、CIFAR-10、CIFAR-100、Location、Purchase、Adult。按照相同的程序对所有这些数据集进行预处理。此外,本文还利用了另外两个数据集,即 News 和 Face,来进行评估。
三轮攻击

从表格中可看出,每一轮攻击都减少了一两个假设,攻击者对目标模型和数据的了解可以越来越少,不禁让人联想起电影《倚天屠龙记》中张三丰教张无忌太极拳,招式忘得愈多,反而学得愈深,颇有老子“绝圣弃智”,“不出于户,以观天下”的味道。
攻击一:不知模型
本轮攻击主要放宽了影子模型设计上的假设,只需使用1个影子模型而且无需知晓目标模型的结构,就可实施高效且廉价的成员推理攻击。不过,训练影子模型时仍需假设影子数据集 $\mathcal{D}_{Shadow}$ 和目标模型的训练数据来自相同的分布。
单一影子模型
这里进一步假设影子模型运用算法和超参数和目标模型相同,在实践中做到这点,攻击者可以使用和目标模型相同的 MLaaS 平台,后面将展示这个假设也可被放宽。
攻击策略有以下三个阶段:
- 影子模型训练:攻击者首先将的影子数据集 $\mathcal{D}_{Shadow}$ 分成两份,用训练集训练影子模型。
- 攻击模型训练:攻击者用训练过的影子模型对所有影子数据进行预测,获得后验概率向量,每个数据点取最大的三个值(若为二元分类则取两个)。一个特征向量被标记为1或0分别代表对应的数据点在或不在测试集中,产生的特征向量和标记接着就被用于训练攻击模型。
- 成员推理:为了推知目标是否在实际训练集中,攻击者向模型查询该数据点并得到后验概率,同样取最大的三个值,然后传给攻击模型来获得成员预测结果。
相比 Shokri 的方法需要使用多个影子模型对每个类别分别进行攻击,本方法只需使用一个影子模型进行攻击,这大大减少了攻击的开销。

结果如 Fig. 1 所示,本攻击方法的精确率和召回率与 Shokri 等人的几乎一致,在部分数据集上甚至表现更优。
目标模型结构
接下来展示如何放宽攻击者必须知道目标模型的算法与超参数的情况这一假设。
首先来看超参数,暂且假设攻击者知道目标模型是一个神经网络但不了解具体细节,先用目标模型的一半参数(即将批尺寸、隐含单元和正则化参数减半)来训练影子模型时,就 Purchase-100 数据集而言,达到了0.86的精确率和0.83的召回率,这和 Fig. 1 中的结果几乎一致;反之,若用两倍参数来训练影子模型时,表现稍显逊色,但仍达到了0.82的精确率和0.80的召回率。在其他数据集上也得到了类似的结果,这证明了成员推理攻击的灵活性:无需知道模型的超参数也能有良好的性能。
接着再假设攻击者不知道目标模型使用了何种分类算法,首先尝试在影子模型和目标模型的类别不同的情况下直接实施攻击,结果不尽人意。改进的方法是采用组合攻击(combined attack),即将一系列不同的分类器模型组合成一个影子模型,其中每个模型被称为次影子模型(sub-shadow model),具体方法如 Fig. 6 所示
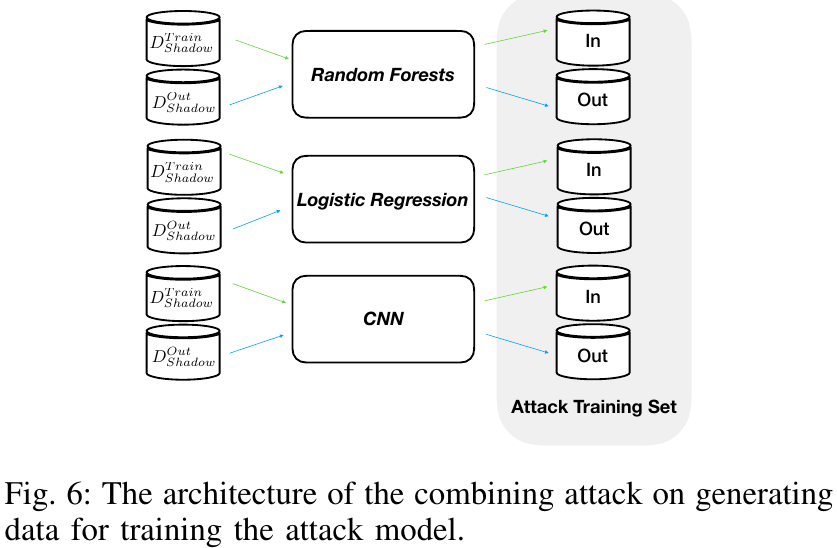
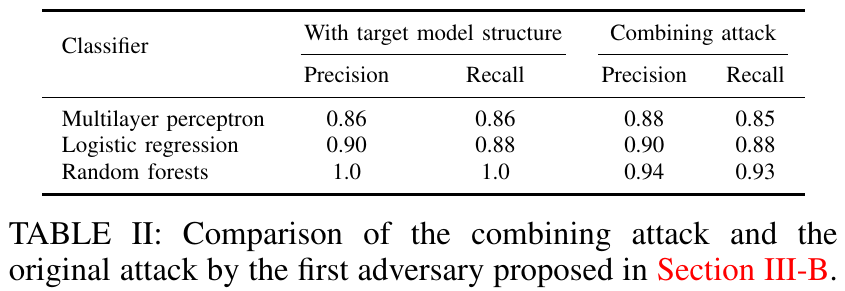
在 Purchase-100 数据集上的结果证明,和上一部分所展示的攻击方法相比,在目标模型采用多层感知器和逻辑回归时,组合攻击的表现毫不逊色,而当目标模型采用随机森林时,组合攻击的性能就有所下降。

攻击二:不知数据
本轮攻击放宽了对数据来源的假设,攻击者不再拥有与目标模型的训练数据同分布的数据集,在此情形下,Shokri 等人提议多次查询目标模型以合成数据来训练影子模型,但这种方法只适用于包含二值特征的数据集,而且每合成一个数据点就需要向目标模型发起156次查询,这不仅代价高昂,还可能触发 MLaaS 的警戒机制。与之相比,本方法就能用于攻击在任何数据上训练的机器学习模型,且没有上述任何限制。
本攻击的策略接近于第一轮攻击,区别在于影子模型所使用的数据集不再与目标模型的训练数据同分布,此种攻击可被称为数据转移攻击(data transferring attack)。在此影子模型并非用于模仿目标模型的行为,而只用于概括机器模型训练集中数据点的成员状态。由于只有最大的三个(对二值数据集来说是两个)后验概率会被用于攻击模型,我们可以忽略数据集的类别数不同带来的影响。
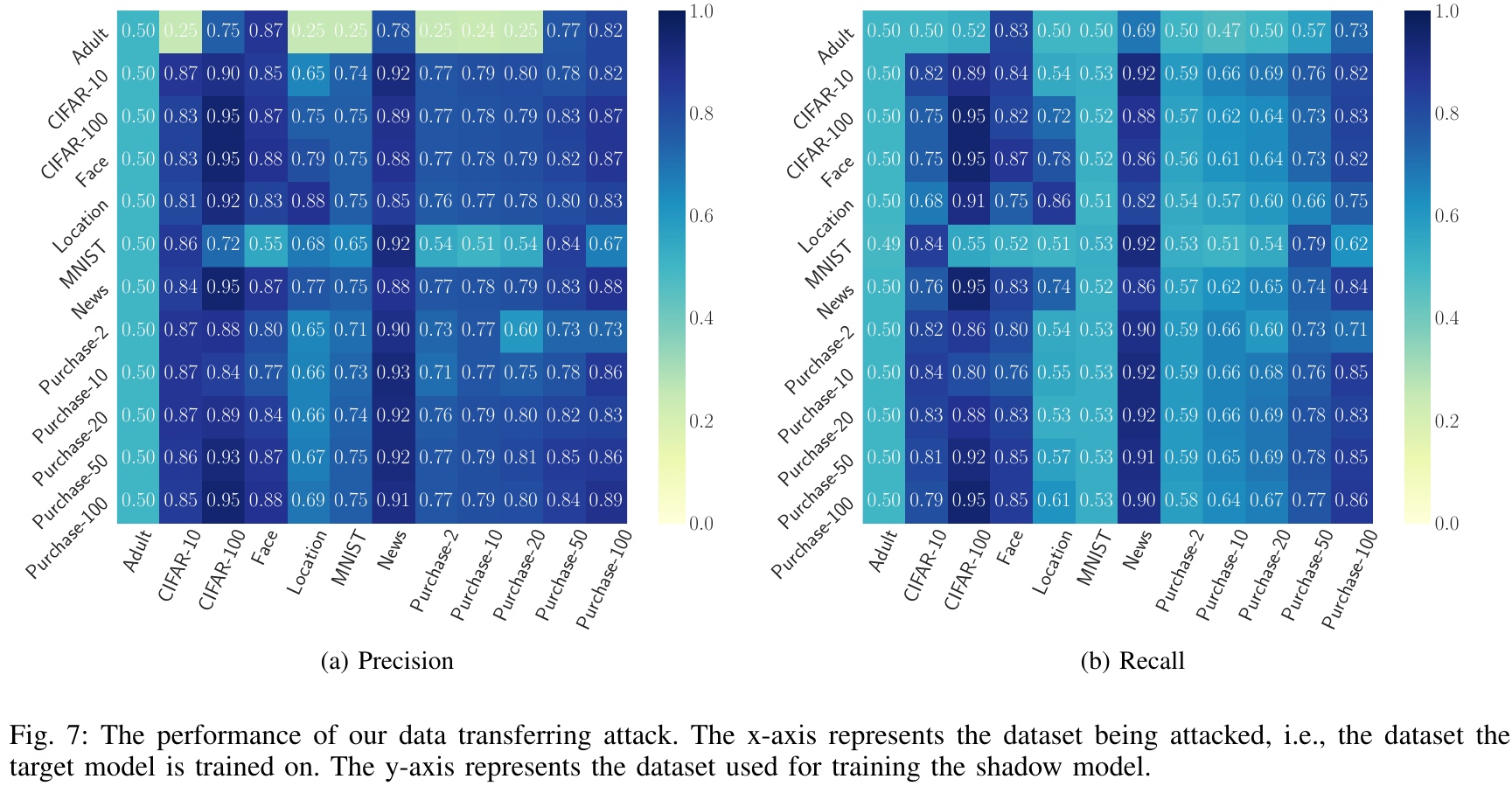
结果如 Fig. 7 所示,和对角线上第一轮攻击的结果相比,本轮攻击在许多场景下都有接近的表现,如使用 Face 数据集攻击 CIFAR-100 数据集,无论是精确率还是召回率,结果都是0.95,和第一轮攻击相同。在一些场景下,本轮攻击的结果甚至优于第一轮攻击。更有意思的是,在很多场景下,不同来源的数据集能够有效地相互攻击,如 News 数据集 和 CIFAR-100 数据集。
攻击三:我好像在哪见过你
本轮攻击不再需要训练任何影子模型,也无需知晓目标模型及其数据分布,攻击者拥有的只是向目标模型查询目标数据点 $X_{Target}$ 得到的后验概率 $\mathcal{M}(X_{Target})$ 。尽管 Yeom 等人提出过类似的攻击,但他们的方法需要知晓目标数据点的分类标签,这有时是难以获得的,而本方法的适用场景就更广泛。
本攻击模型的实现是一个无监督二元分类器,攻击者先获得 $\mathcal{M}(X_{Target})$ ,再拿最高的后验概率和一个确定的阀值相比,若高于阀值,则预测此数据点在目标模型的训练集中。选取最高值作为特征是基于如下推理:模型对训练过的数据点表现得更自信,体现在结果上就是,成员数据点的后验概率最大值高于非成员数据点。这是一种朴素的信念,但也符合我们的直觉,人对熟悉的事物表现得更自信,模型亦是如此。
阀值的选取可根据需求而定,若更关注精确率则用高阀值,更关注召回率则选择低阀值。本文也提供了选择阀值的通用方法。
综合三轮攻击的结果,可以证明成员推理攻击是非常广泛地适用的。
防御机制
丢弃
完全连通的神经网络包含大量的参数,容易发生过拟合,而丢弃(dropout)是减少过拟合的一种非常有效的方法。在一个完全连通的神经网络模型中,通过在每次训练迭代中随机删除一个固定的边缘比例(丢失率)来执行该算法。本文对目标模型的输入层和隐藏层都应用了丢弃法,默认的丢弃率设为0.5,因为实验结果表明过高或过低的丢弃率都会降低模型性能
模型堆叠
丢弃只适用于神经网络模型,而模型堆叠(model stacking)与所选择的分类器无关,这种机制的背后的原理在于,若目标模型的不同部分使用不同的数据子集进行训练,则完整的模型就不易过拟合,这可以通过集成学习(ensemble learning)实现。
成果总结
为了证明成员推理攻击的广泛性,本文提出了三轮攻击,逐渐放宽了假设。
第一轮攻击只用到了一个影子模型,大大降低了攻击成本,还通过组合攻击使得攻击者无需了解目标模型的种类。
第二轮攻击只用放宽了对数据来源的要求,数据转移攻击在实现成员推理攻击效果的同时也更具有普适性。
第三轮攻击具有最少的假设,攻击者无需构建任何影子模型,攻击是通过无监督的方式进行,在这样的场景下,成员推理仍然卓有成效。
本文对攻击效果的综合评估充分证明了各种机器学习模型中数据成员的隐私所面临的威胁,为了遏制攻击,本文提出了两种防御机制:丢弃和模型堆叠。由于模型的过拟合程度和对成员推理的敏感性之间存在联系,这些机制也正是为减少过拟合而生。大量评估证明这些防御机制在抵抗成员推理攻击的同时也维持了模型的高可用性。
参考文献
[1] Salem, Ahmed et al. “ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models.” Proceedings 2019 Network and Distributed System Security Symposium (2019).
[2] Shokri, R. et al. “Membership Inference Attacks Against Machine Learning Models.” 2017 IEEE Symposium on Security and Privacy (SP) (2017).
[3] Pyrgelis, Apostolos et al. “Knock Knock, Who’s There? Membership Inference on Aggregate Location Data.” ArXiv abs/1708.06145 (2018).
[4] Jia, J. and N. Gong. “AttriGuard: A Practical Defense Against Attribute Inference Attacks via Adversarial Machine Learning.” USENIX Security Symposium (2018).
[5] Yeom, Samuel et al. “Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting.” 2018 IEEE 31st Computer Security Foundations Symposium (CSF) (2018): 268-282.
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。