MdPerfFuzz: 理解并挖掘 Markdown 编译器的性能 bug

文章目录
论文信息
原文作者:Penghui Li; Yinxi Liu; Wei Meng
原文标题:Understanding and Detecting Performance Bugs in Markdown Compilers
发表会议:ASE 2021 (The 36th IEEE/ACM International Conference on Automated Software Engineering)
原文链接:https://seclab.cse.cuhk.edu.hk/papers/ase21_mdperffuzz.pdf
代码链接:https://github.com/cuhk-seclab/MdPerfFuzz
问题背景
Markdown 被广泛使用在 GitHub 等代码托管平台和 WordPress 等 CMS 系统中,Markdown 编译器中可能存在的漏洞却没有得到重视,尤其是性能问题容易成为 DoS 攻击面。
作者调研了主流 Markdown 编译器的 49 个性能 bug,观察出根本原因是 the specific ways that Markdown compilers handle the language’s context-sensitive features,回溯法在特制输入下会达到最坏时间复杂度,而若强行施加上限则影响功能性。
由于性能问题的成因是 algorithmic complexity,本文重点关注 CPU-exhaustion 而不是 memory,在 17,18 年分别有 SlowFuzz 和 PerfFuzz 等工作。而本文开发了 MdPerfFuzz 这一工具以高效地发掘 Markdown 编译器中的漏洞,并基于 trace 得到的路径相似性去除重复结果。
理解现有 bug
收集 CommonMark specification 和 4 个代表性编译器的 49 个 bug,从以下角度分析:
-
发现方式:大部分是手动审计得到,仅有 5 个是用 OSS-Fuzz 等自动工具获得
-
发现和修复时间:2015 年前很少有报告 bug,2018-2020 年来数量持续增长(可能与 markdown 的流行趋势吻合),而大部分 bug 在报告一月内被修复,少部分修复极慢的 bug 是通常与 CommonMark specification 本身的模糊性有关,一些 patch 直接导致对 spec 的修改。
-
根本原因:
- 主要是 worst-cases in super-linear algorithms
- unoptimized code 导致多余开销
- problematic implementations 未能完全符合 CommonMark specification,比如缺乏 unicode 支持导致死循环。
解决方案:enforcing limits,或者引入 logic change,比如优化低效代码或重写 regex。
MdPerfFuzz 系统设计
静态分析方法假阳率过高,因此本文选择使用 fuzz 发掘性能漏洞,但面临着两大挑战,其一是 Markdown 文档的搜索空间太大,难以高效生成测试输入以发掘 bug,其二是多个独特的测试输入可能引发同一个 performance bug,且无法通过 memory footprints 来区分,针对以上问题,本文开发了 MdPerfFuzz,架构如下图:
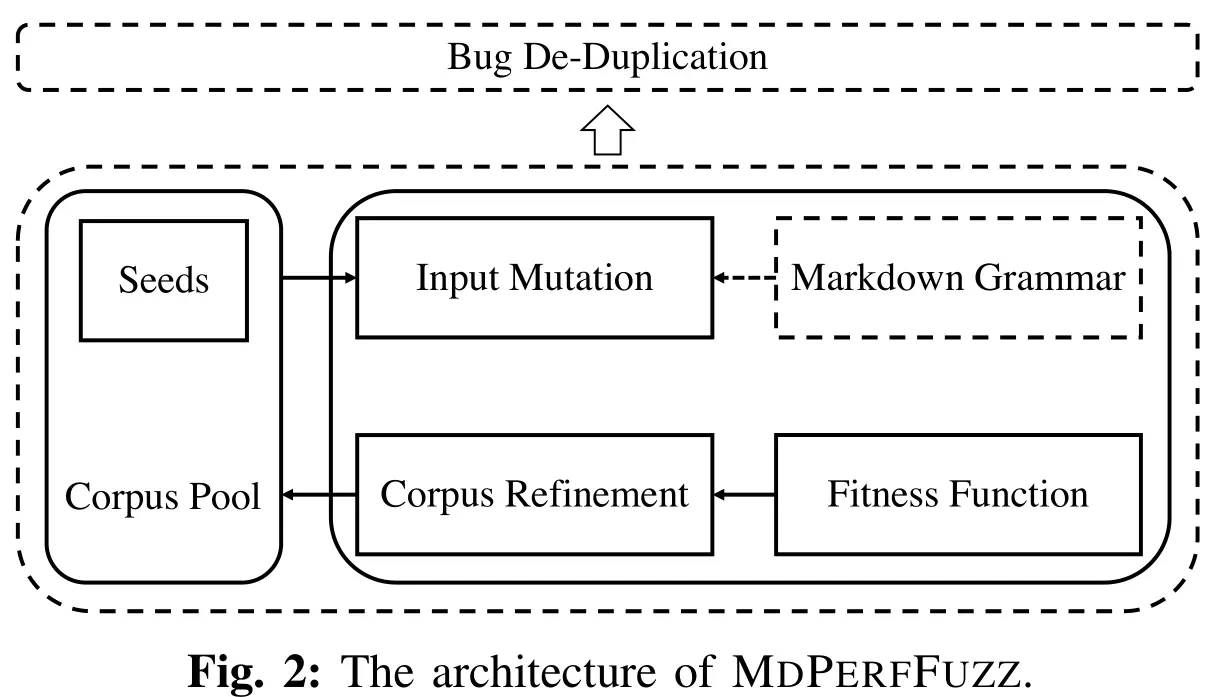
具体实现基于之前的 SOTA 工作 PerfFuzz,其本身也是 AFL-based。而 Markdown 语法会被 ANTLR4 编译得到 parser,引入 syntax-tree based mutation strategy 作为一个扩展,修改 AFL 的 showmap 功能来 trace execution 获得 CFG edge hit counts。
Syntax-Tree Based Mutation Strategy
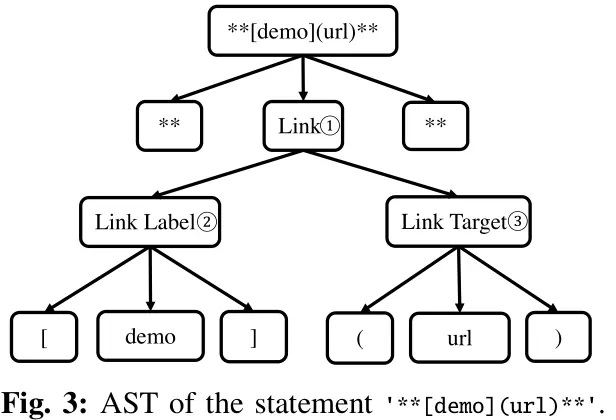
作者花大量时间分析 CommonMark specification 并对其语法建模,给定的测试数据会先被解析成 AST,而后遍历 AST 并随机替换其中的子树
Fitness Function and Performance Bug Detection
覆盖反馈的 fuzz 工作基本都以新覆盖的代码量为指标,但对于性能 bug 来说,循环迭代次数非常关键,和之前的工作类似,MdPerfFuzz 考虑 CFG edge hit counts,即 CFG 中一条边被同一测试数据访问的次数,能够探索 computationally expensive paths。
之前的工作依赖手动分析来判别 bug,而 MdPerfFuzz 以 total execution path length 为指标,即 CFG edge hit counts 之和,先用大量普通数据获取通常情况下的执行表现,计算 total execution path length 的均值和标准差,根据切比雪夫不等式筛选与均值偏离 k 倍标准差的 case,判定为 bug。
Bug De-Duplication
与 memory corruption 不同,同一 performance bugs 可能拥有不同的 call stack,而本文提出的去重方法基于 execution traces 的相似程度。对每个 bug report 构造一个 edge-hit-count vector,第 i 个元素代表 CFG 第 i 个结点的 hit count,对两个向量计算 cosine 值即为其相似程度,若超过一定阈值即认定为同一 bug。
实验效果
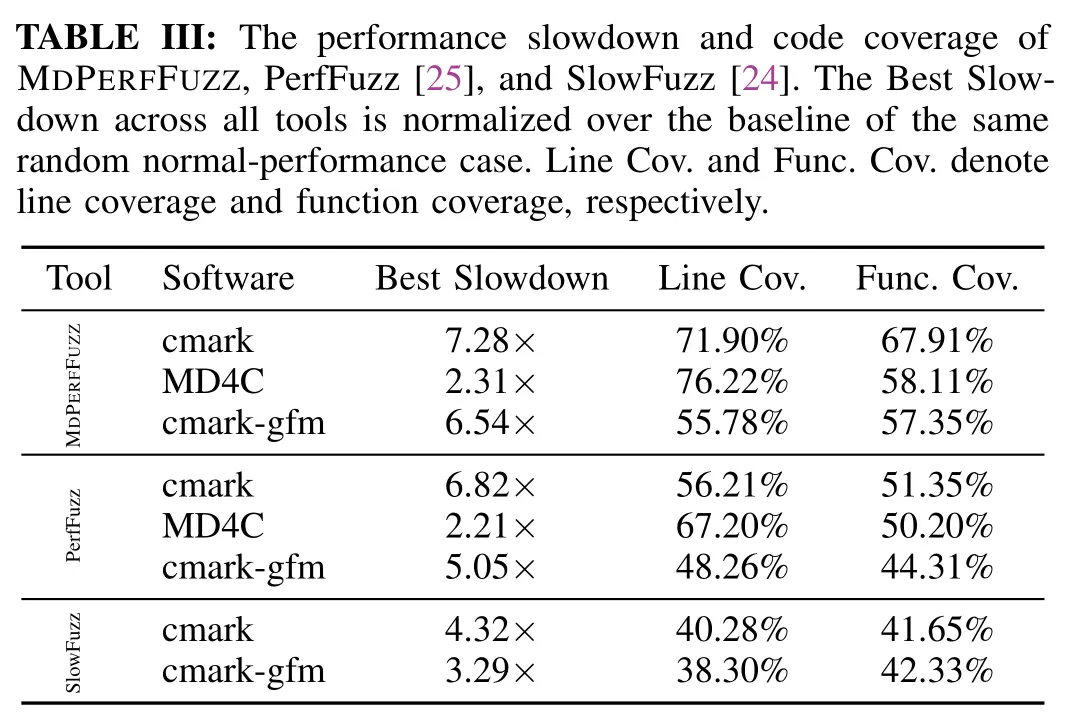
实验一:横向对比挖掘 performance bug
限制 6 小时,输入大小 200 字节,并根据经验取切比雪夫不等式中 k=5,相似度阈值为 0.91
像在其他工作中一样限制输入大小是不让搜索空间过大,为了验证在实际场景中的真实影响,还可根据发现的 pattern 构造更大的输入,手动分析得到新 bug。但观察假阳案例会发现手动构造更大的输入有时反而不影响性能,因为开发者可能已经设了限制,过大输入会直接被舍弃。
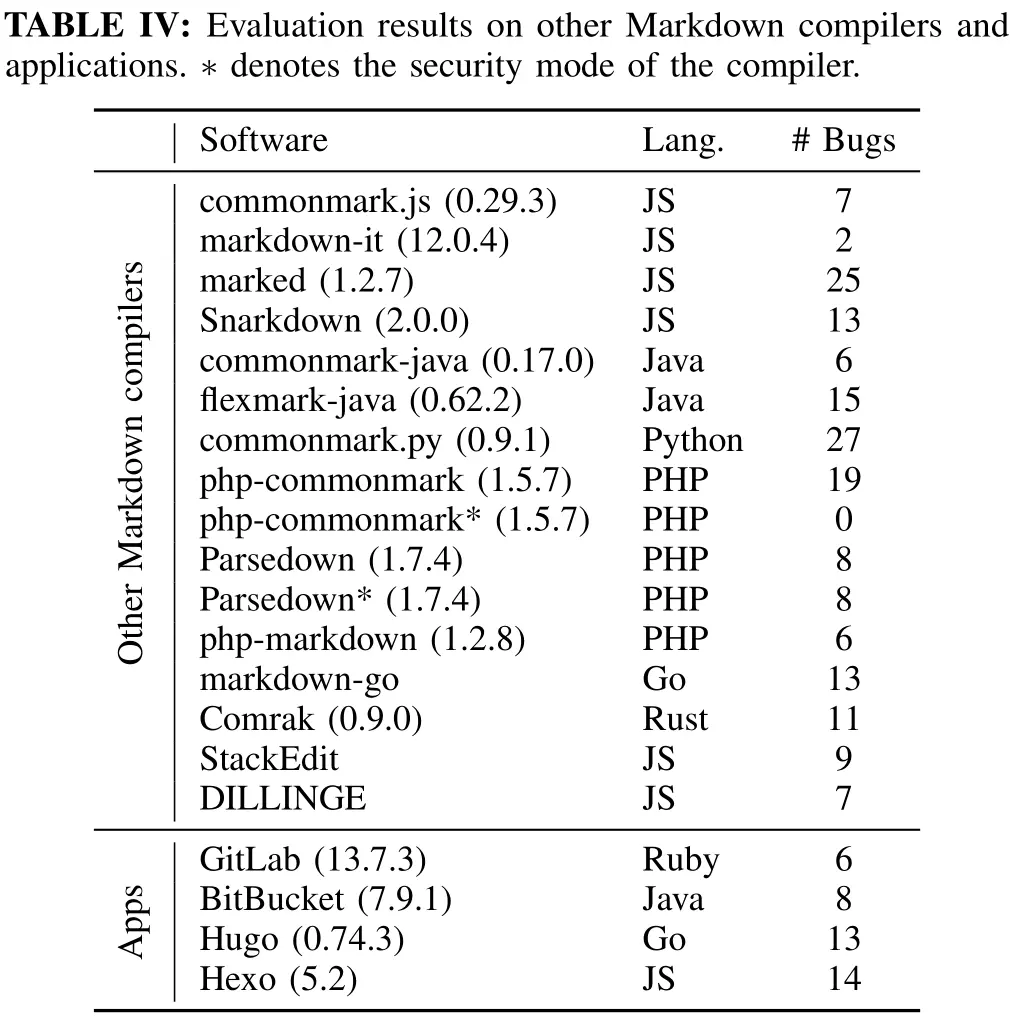
实验二:研究其他 Markdown 编译器的漏洞
利用 MdPerfFuzz 得到的 exploit 构造扩展的 dataset 以研究非 C/C++编写的 Markdown 编译器,以及其真实软件中的应用,比如代码托管平台上的 Markdown 渲染器和静态网站生成器(如 Hugo)。
结果也发现了许多 bug,虽然由于不能 trace 而无法去重,但构造的测试输入已被分类成了 45 种 pattern 以针对特定的 feature,故而可以认为是互不相同的。
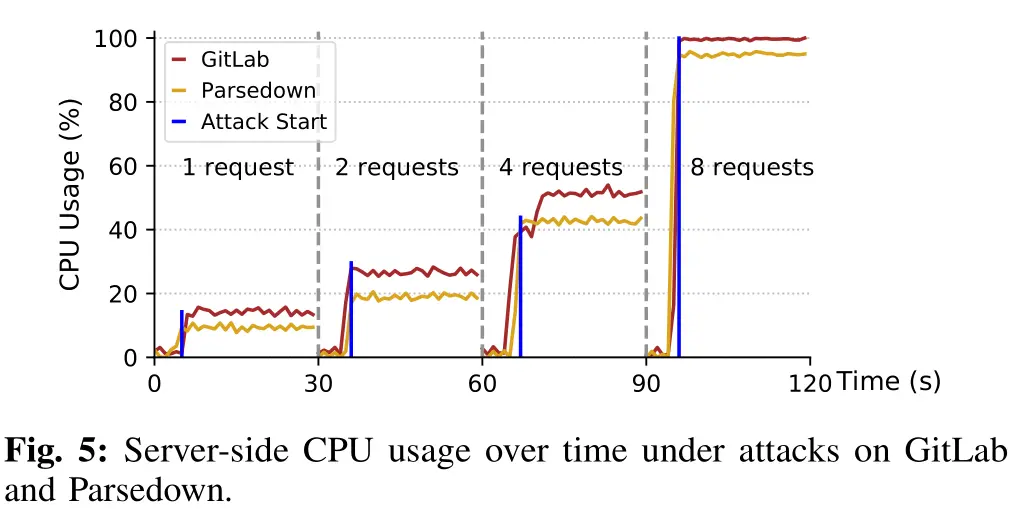
如果是服务端渲染 Markdown,可能造成较大的危害,以部署在 Nginx 上的 GitLab 和 PHP 模块 Parsedown 为例,两分钟内发起 8 次请求即可将 8 核 CPU 负载打满。
讨论与相关工作
Mitigating performance bugs:保护机制需在功能性和安全性之间取得平衡
Bug de-duplication:Trace-based analysis 很有效但不是所有语言都有插桩工具可用,未来可考虑语言无关的去重方式比如转成某种 IR 进行
相关的研究领域有对桌面/移动/服务器端的应用比如浏览器上的性能 bug 进行研究,还有 pypi,npm 生态系统中的 ReDoS 问题进行研究,编译器中的 bug 也有人研究,但没有重点关注性能问题,本文对 Markdown 编译器中性能 bug 的研究也可以拓展到其它类型的 bug,比如 memory corruption,也可能扩展到其它语言。
在研究方法上,静态分析可以用来检测 vulerable pattern,比如 repeated loops,fuzz 等动态执行方法也得到广泛应用,比如 grammar-aware fuzzing 可以生成语法正确的输入,learning-based fuzzing 用神经网络模型对 AST 子树进行替换。
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。