Magma: A Ground-Truth Fuzzing Benchmark

文章目录
之前我们分享过 ISSTA 2022 中一篇对静态分析检测漏洞效果进行评估的文章,与其他使用 LAVA-M 合成数据集的工作不同,它的数据集主要基于 Magma,包含了一百多个真实的 CVE。而 Magma 原本是 Mathias Payer 领衔的 HexHive 组发布的 ground-truth fuzzing benchmark,论文发布于 2020 年底,代码目前仍有人维护更新,今天我们就来炒一炒冷饭,看看同样是「熔岩」的 Magma 比 LAVA 猛在哪里。
官网地址:https://hexhive.epfl.ch/magma/
论文地址:https://hexhive.epfl.ch/publications/files/21SIGMETRICS.pdf
代码地址:https://github.com/HexHive/magma
视频地址:https://www.youtube.com/watch?v=N6kePNadUV8
背景动机
Fuzzing 技术种类繁多,但不管是黑盒还是白盒,基于语法还是变异,本质上都是非常随机的过程,这使得评价和比较不同的 fuzzer 极为困难。
Klees 等人在 CCS 2018 年的工作 Evaluating Fuzz Testing 调研了 32 篇 fuzzing 论文,发现没有一篇能提供足够的细节来证明其 fuzzer 的改进,他们强调了一些评估 fuzzer 工作的普遍标准:
- Performance metrics: 触发 crash 的数量和代码覆盖率都是广泛应用的指标,但没有证据表明两者和发现漏洞的数量有强关联,而判定 ground-truth bug 需要大量专家经验
- Targets: 要有多样性和现实性
- Seed selection: 在各论重复实验和不同 fuzzer 评估中应当保持一致
- Trial duration (timeout): 一次 trial 是指 fuzzer 在目标程序上的一次运行,时间必须固定
- Number of trials: fuzz 这种随机性强的技术需要大量重复,fuzzing campaign 是指在同一目标上运行固定次数的 trial
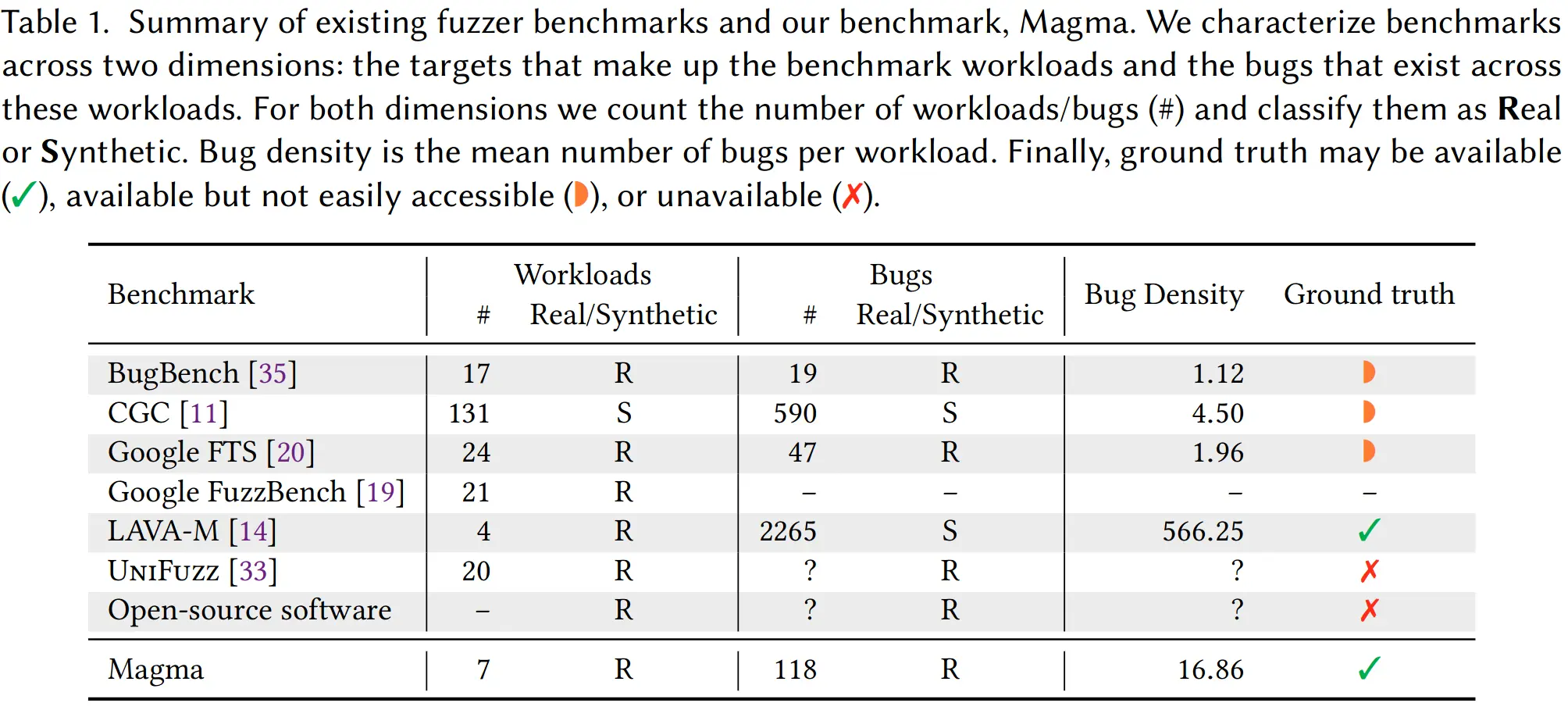
本文对比了现存的 fuzzer benchmark,不是 target 数量少就是 bug 种类单一,用人工合成 bug 的难以评估 fuzzer 在真实复杂软件上的效果,用真实 bug 的分布都较为稀疏而且缺乏 ground truth。
那么理想的 benchmark 应该满足哪些属性呢?本文从以下三个方面考虑:
-
Diversity (P1): bug 和目标程序都要足够多样且具有现实性
-
Verifiability (P2):要提供 easy access to ground-truth metrics,描述 bug 如何被 reach, trigger 和 detect
-
Usability (P3):提供的目标程序集上要有大量可发现的 bug,且易于检验并报告 fuzzer 进展和效果
Magma 的方法论
目标程序的多样性分析
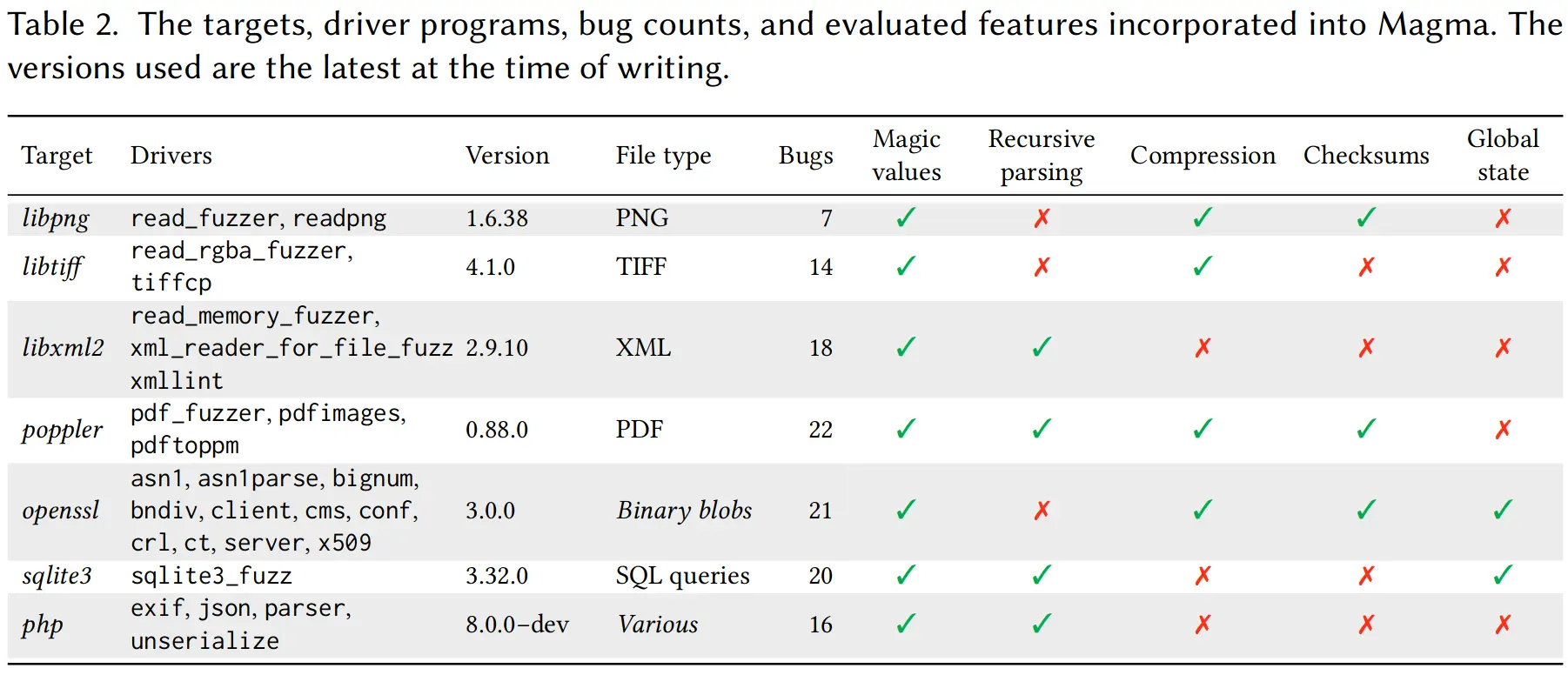
首先目标程序(即含有 bug 的被测程序)的选择,论文发布时只有 7 个目标程序(截止到 2022 年 8 月,最新版是 v1.2 已经有 9 个目标程序)。文中为了表现其选择的多样性,列了一张表格说明各程序的不同特性。
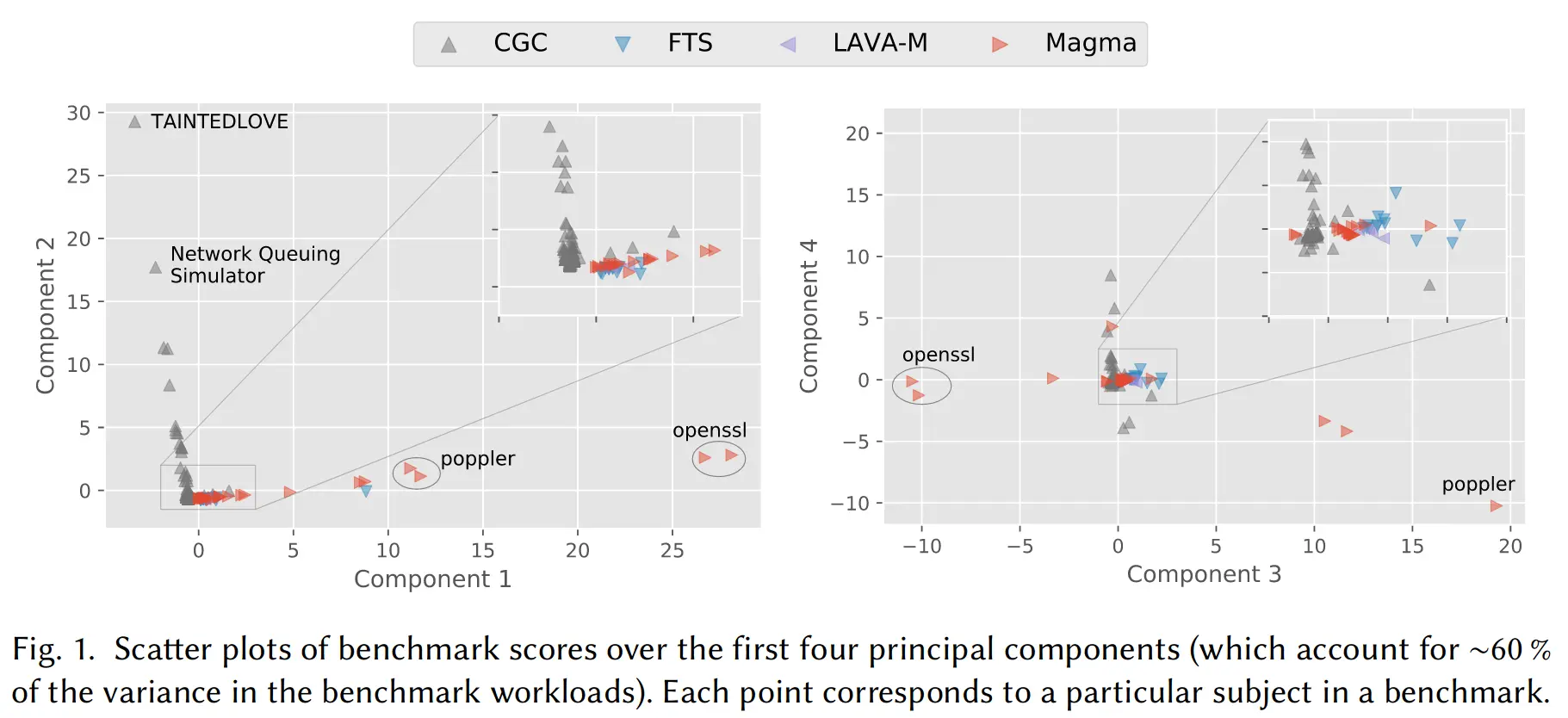
为了和现有其他 benchmark 比较目标程序的多样性,从中选取了两百多个 subject(就是 fuzz 可执行程序,文中说是 libFuzzer 的术语,但网上查证没有结果),使用 Intel Pin 来记录其指令执行,并按照 Intel XED 将指令分类,最后做了一个主成分分析(Principal Component Analysis, PCA)来显示不同 benchmark 所用目标程序的差异,取前四个主成分,在二维平面上的结果如下图所示。
漏洞多样性和前向移植
在 Bug 的选择上本文也和其他 benchmark 做了比较,Magma 所选 bug 覆盖的 CWE 种类数仅次于 CGC,bug 密度(平均每个目标程序所含的 bug 数)仅次于 LAVA-M,但其他两个都只用了合成的 bug,不能反映现实世界中漏洞的多样性。
值得一提的是 Magma 使用 forward-port 把 bug 插入到软件的最新版本中,而不是像现有 benchmark 使用受 bug 影响的老版本,这样做很明显的好处就是易扩展,能插入任意 bug 而不受版本限制。插入 bug 首先要从漏洞报告中找到包含修复的 commit(s),把修复后的代码改回到原状态,并识别出能触发 bug 的状态,编写布尔表达式来作为识别 bug 触发的 oracle,这些过程不太可能全都自动化,故所有 bug 都是手动移植并验证的。
精细的性能评价指标
前文已经讲过 crash count 和 code coverage 不足以评价检测漏洞的效果,而本文作者认为单纯对 bug 计数粒度也不够细,还要区分 reach, trigger 和 detect:代码覆盖到相应的路径只是在控制流上满足条件,还要满足对应的程序状态即数据流的条件才能够触发 bug,但即使如此 fuzzer 也未必能成功检测到错误,sanitizer 更擅长检测内存和算术上的错误,而资源耗尽导致的拒绝服务型漏洞往往要在被触发后等待至超时才会被发现,语义和逻辑型漏洞则更加隐蔽。现在有一些工作意在检测特定种类的漏洞,所以作者认为 bug detection rate 也是评价 fuzz 技术进展的一个重要维度。
重要问题与 Magma 的选择
Magma 专注于评估 fuzzing,并不试图成为通用的漏洞检测 benchmark,所以专门考虑了一些 fuzzing 特有的问题,其在设计和实现上的一些选择也正出于此,这里只挑出一部分介绍。
Weird States
当 fuzzer 触发了一个 bug 但未能检测出并继续执行时,程序实际上进入了非确定性的状态,即 [weird state](http://www.dullien.net/thomas/weird-machines-exploitability.pdf),在此之后收集到的信息都是不可靠的,因此 Magma 只收集进入 weird state 之前的 oracle data,文中举了下图中的例子来说明 weird state 可能导致意料之外的漏洞触发。

Static Benchmark
作者认为 Magma 和 SPEC CPU 等其他常见的性能 benchmark 一样都属于 static benchmark,好处是包含现实应用程序,缺点是可能导致开发者专门对 benchmark 进行 overfitting,动态合成的 benchmark 能克服 overfitting 问题,但是目前的技术很难合成反映现实开发场景的大型程序。好在 Magma 的 forward-porting 可以很容易地更新目标程序,从而一定程度上防止了 overfitting。
Leaky Oracles
在 benchmark 中包含 oracle 可能泄漏一些信息导致对 fuzzer 探索能力的干扰,比如 fuzzer 检测到作为 if 语句的 oracle 就会尝试生成满足分支条件的输入数据,可能造成 overfitting。为此 Magma 使用了 always-evaluate memory writes,定制了 x86 汇编以在单个基本块中进行逻辑运算,避免短路行为,下图就是 Magma 在程序中插入 canary 的一个例子。

Proofs of Vulnerability
为了增强对插入 bug 的信心,对每一个 bug 最好要提供一个 proof of vulnerability (PoV) 来验证 bug 可以被触发,这无疑需要专业知识和大量人力。只有部分 bug 可以从公开报告中提取 PoV,否则作者就跑很多 fuzz 来尝试获得能触发 bug 的 PoV,如果无法生成就再手动分析触发条件是否能被满足。这段原文只有几行,但背后工作量应该不小。
实验评估
前文其实已经在设计方法上对 Magma 和其他 benchmark 做了很多对比,这里实验评估则是用 Magma 对不同的 fuzzer 进行 benchmark,实验结果可以对比不同 fuzzer 的效果差异,文中还分析了一些特定案例来解释不同 fuzzer 在不同 bug 上表现各异的原因。
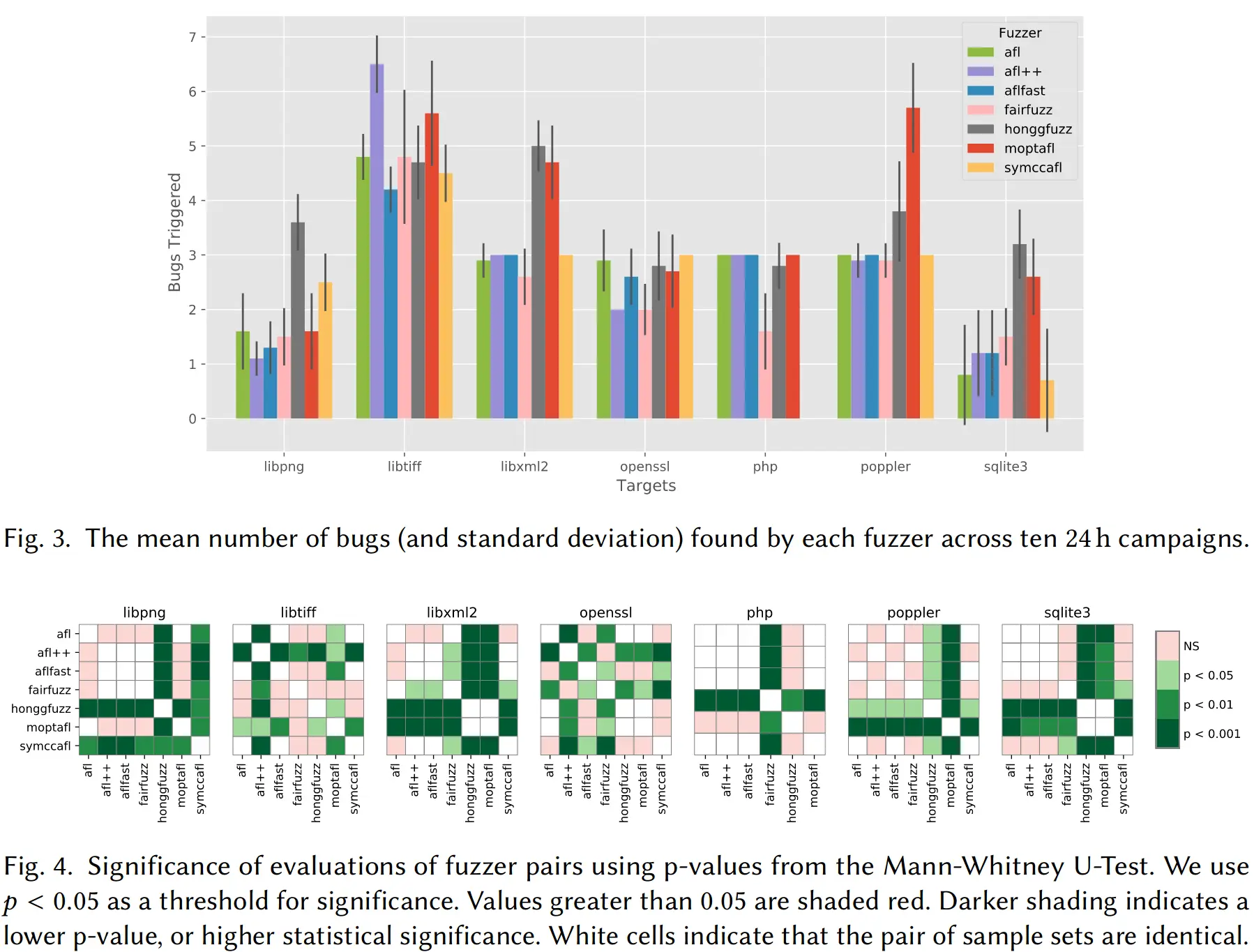
如下图所示,文中对 AFL, AFLFast, AFL++, FairFuzz, MOpt-AFL, honggfuzz 和 SymCC-AFL 一共 7 个 fuzzer 在 7 个目标程序上触发的 bug 数量进行了评估,还使用曼-惠特尼U检验(Mann-Whitney U-test)这个看上去很高深的统计学方法来分析了不同 fuzzer 结果的相似性,结论是 AFL++ 平均 bug 检出量最高,而 AFL, AFLFast, AFL++ 和 SymCC-AFL 在大多数目标程序上表现接近。
此外,文章还用一页篇幅分析了不同 fuzzer 在 reach 和 trigger 不同 bug 上所需的时间,绘制了如下曲线图,文末附录还列出了长长的表格,总之结论类似龟兔赛跑:尽管 honggfuzz 在 24 小时内触发了最多的 bug,但 MOpt-AFL 在长达七天的 long fuzzing campaigns 中成为了最后的赢家。
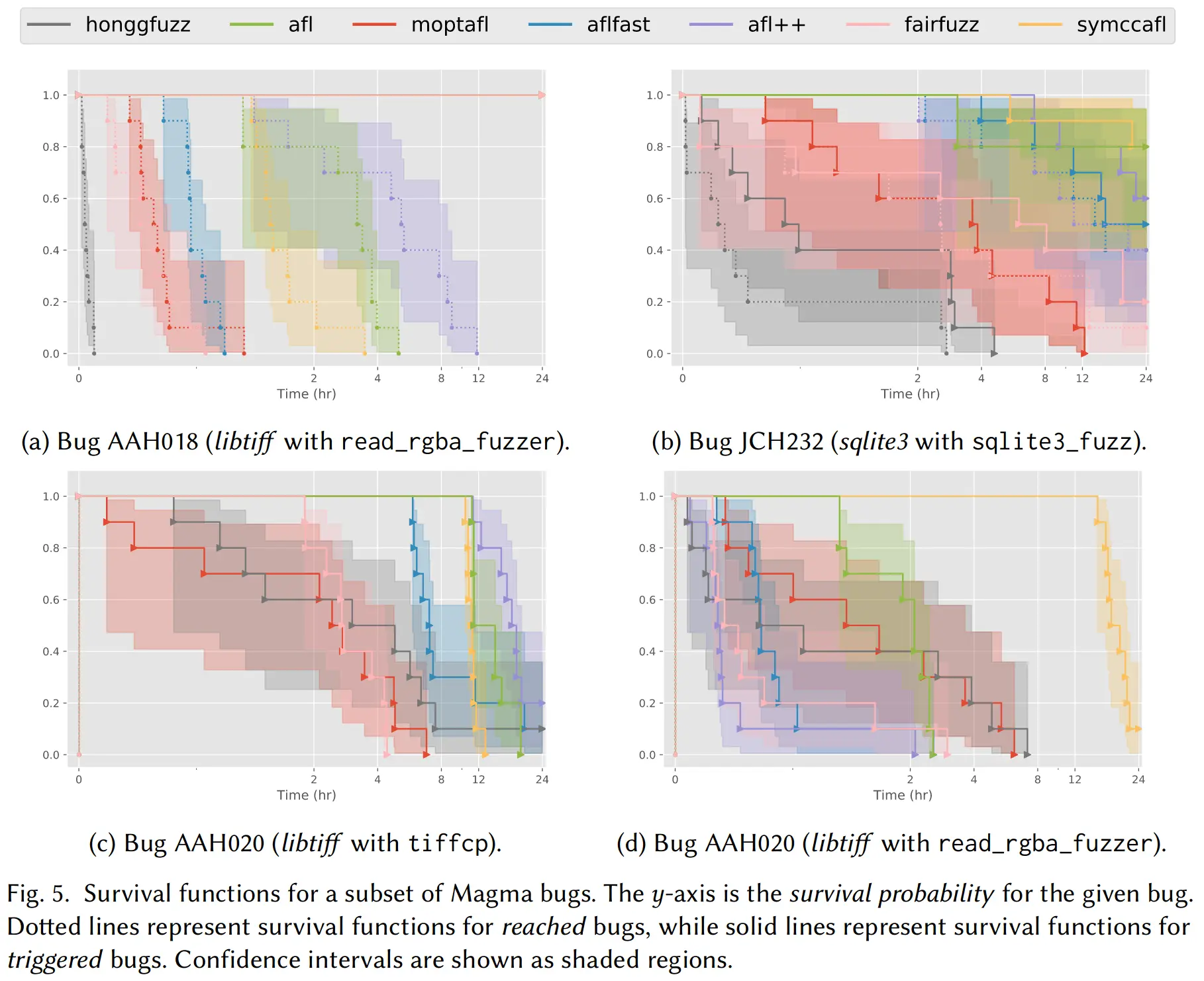
评估部分的最后一段 LAVA-M 再做了下比较,结论就是 LAVA-M 中的 bug 种类太单一,对能检测 magic-value 的 fuzzer 有很明显的倾向性。
总结讨论
文末再次强调 Magma 和其他现有 benchmark 不同之处就在于能提供唾手可得的 ground truth,但也承认总共 118 个 bug 中只有 45% 有能证明触发的 PoV,作者把生成更多的 PoV 作为 open challenge,之后 Magma 也会持续进化以获得更多带 PoV 的 bug。
Magma 的插桩没有收集关于 detected bug 的信息,因为 detection 是 fuzzer 的特性而不只和 bug 本身有关,但可以通过 post-processing 来评估这一指标,结论就是老生常谈的 bug 不限于 crash,需要考虑 bug 的不同表现。就检测 bug 的不同时机而言,reach 主要体现路径探索能力,trigger 和 detect 则更多依赖约束生成求解能力,关注 detect 也能帮助识别哪些 bug 更不容易被现存的 santitization 技术发现。
个人认为比较可惜的一点是没有对 fuzzer 在检测不同种类 CWE 的 bug 上的效果做一个对比,文中甚至没有列出具体覆盖了哪些 CWE,而之前介绍 ISSTA 2022 上 An Empirical Study on the Effectiveness of Static C Code Analyzers for Vulnerability Detection 这篇工作倒是重点着墨 CWE 分类。
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。