LibAFL:构建模块化可复用 fuzzer 的框架

如今系统安全方向的论文在代码开源上已经展开了激烈的军备竞赛,一篇文章动辄成千上万行的代码量,今天我们推荐的这篇 LibAFL 则更胜一筹,先有开源工具再顺便写了篇论文,还发到了 CCS 2022。
Fuzzing 研究百花齐放,工具层出不穷,很多都基于 AFL/AFL++ 进行二次开发,互相之间却又不兼容,让引入新特性和验证工作效果非常麻烦,本文作者身为 AFL++ 社区的主要维护者,对目前 fuzzer 界分裂的现状深感不满,认为这不仅是工程问题,更反映了目前对 fuzzer 的实体(entity)缺乏一个标准的定义,于是他提出了如下 9 个实体来定义 modern fuzzer 的组成:
- Input:程序的输入。重点是其在 fuzzer 内部的表现形式,最常见的就是 byte array,不过其不适用于一些特殊场景,比如 grammar fuzzer 会将输入存储为 AST 等结构,在发送给目标程序前才会序列化为字节序列。
- Corpus:输入和其附属元数据的存储。若位于内存中会导致较大的资源消耗,若位于磁盘则方便用户观察 fuzzer 的状态,代价是速度受到磁盘读写的瓶颈制约,主流 fuzzer 大多选择后者。此外,存储时还要区分有助于进化的 interesting testcase 和最终触发 crash 的 solution。
- Scheduler:从 corpus 中选取 testcase 的调度策略。最朴素的即先进先出或随机选择,近年来也有工作利用调度来给 testcase 排优先级或是防止 testcase 爆炸。
- Stage:定义对单个 testcase 进行的操作(action)。在 scheduler 选择了一个 testcase 后,fuzzer 会在其上进行分阶段的操作,比如 AFL 中的 random havoc stage 会对输入进行多种变异操作,许多 fuzzer 都有 minimization phase 以在保持覆盖率的同时减小 testcase,这也是一种 stage。
- Observer:提供一次执行目标程序的信息。从对 fuzzer state 的影响看,observer 的快照应当和执行本身应当是等效的,这样在分布式 fuzzer 或是执行很慢的目标程序上会比较有帮助。覆盖导向型 fuzzer 中常用的 coverage map 就是一种 observer。
- Executor:用 fuzzer 的输入来执行目标程序。不同 fuzzer 在这方面区别可能很大,libFuzzer 这种 in-memory fuzzer 只需调用 harness 函数,Nyx 这种 hypervisor-based fuzzer 则每次执行都要从快照重启整个系统。
- Feedback:将程序执行的结果分类以决定是否将其加入 corpus。大多数情况下 Feedback 和 observer 紧密相连但又有所不同,feedback 通常处理一个或多个 observer 报告的信息来判断 execution 是否 “interesting”,是否是满足条件的 solution,比如可观测的 crash。
- Mutator:从一个或多个输入生成新的 testcase。这部分通常是定制 fuzzer 时最常改动的,不同 mutator 可以组合,往往还和特定的输入类型绑定,比如传统 fuzzer 中常见的是比特级别的变异,比如 bit flip 和 blocks swapping,而 grammar fuzzer 中的 mutator 则可交换 AST 上的节点来进行变异。
- Generator:凭空产生新的输入。有随机生成的,也有 Nautilus 这种基于语法的。
基于上面这许多抽象的定义,作者用 Rust 实现了 LibAFL,有三个主要组成部分:核心组件 LibAFL Core, 在目标程序中运行的 LibAFL Targets,提供编译 wrapper 的 LibAFL CC,除此之外还包含了几个插桩后端(Instrumentation Backends),下图描绘了 LibAFL Core 的架构:
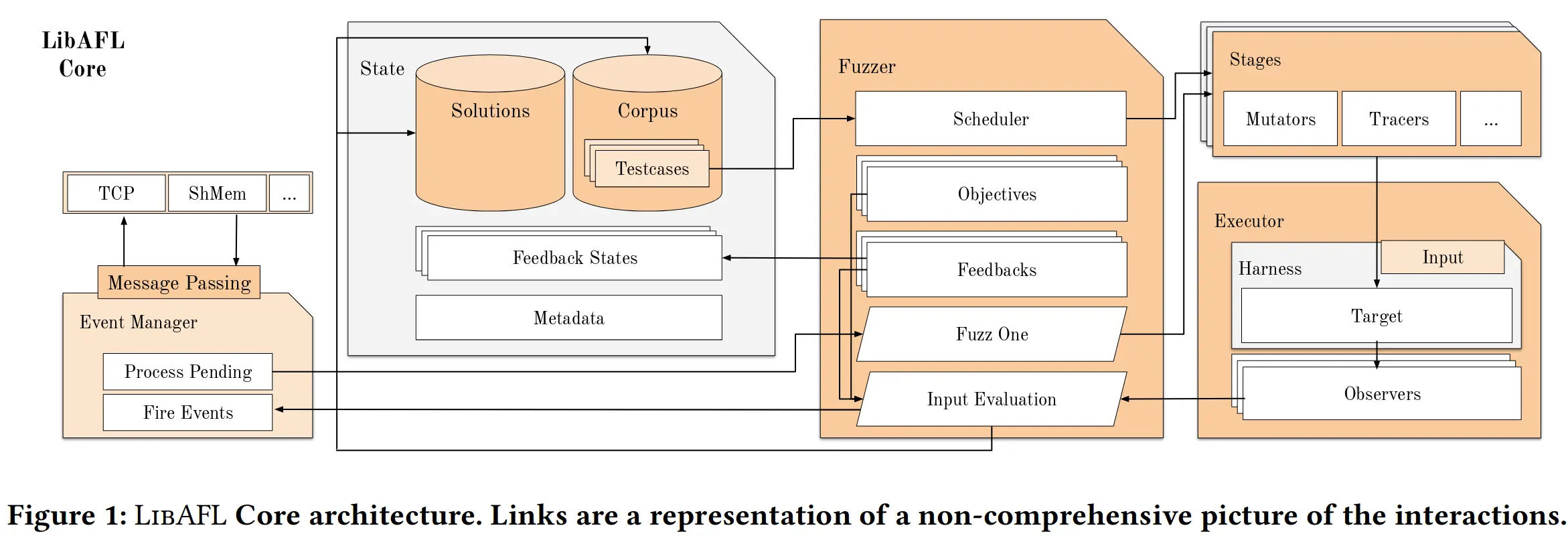
从图中可以看到 LibAFL 的组成部分,除了 State, Fuzzer 和 Events Manager 这三个大模块之外,大部分都一一对应前文所定义的 9 大实体。总之,模块化的设计让 LibAFL 天生具有极强的 Extensibility,基于 Rust 实现,独立于平台和不依赖标准库带来了 Portability,Event Manager 使得多节点并行 fuzz 的 Scalability 成为可能,这便是 LibAFL 设计之初所遵循的三个原则。
实验部分主要是用 LibAFL 实现了各种 fuzzing 技术并评估其在解决不同问题上的效果,这里就不一一展示了,看完只觉得略有些恐怖,LibAFL 就像手术刀一样把所有 fuzz 技术都剖析得清清楚楚,有没有可能之后所有的 fuzz 工作都需要用 LibAFL 实现一下才能服众?
在文末作者还介绍了目前的缺陷主要是缺少链接时优化(Link Time Optimization) passes,不能分析整个程序的控制流图,无法实现 directed fuzzing,不过这一特性的支持只是时间问题。未来可以着重关注并实现的强大功能是 concolic tracing API,可以解决传统 concolic fuzzer 中 concolic engine 和 fuzzer 难以协作和伸缩性差的问题。
简要介绍完了论文,我们再来关注一下项目本身一些有趣的点:
作者选择用 Rust 实现 LibAFL,并在文中特意强调了零开销抽象带来的好处,无独有偶,在结束不久的的第二届中国 Rust 开发者大会上,陈鹏老师展示了如何用 Rust 从零实现 fuzzer,他发表在 IEEE S&P 2018 的 Angora: Efficient Fuzzing by Principled Search 就是「第一个用 Rust 实现的开源 fuzzer」,详情可见 SHU 开源社区的这篇推文,总之我们期待 Rust 在安全研究中得到广泛应用。
其他论文放出的开源代码往往只有作者自己维护,而 LibAFL 则从一开始就是 AFL++ 社区的开源项目,如果你感兴趣,就有机会直接贡献代码。本文第三作者就在 Google Summer of Code 2021 中为 LibAFL 实现了 AFLFast 和 MOpt 这两种 scheduler,目前已是项目的主要维护者之一,而今年的 Google Summer of Code 则有另一位学生将 Nyx 引入 LibAFL,这可能说明了参与开源和进行研究也是相辅相成的,总有人在论文发到飞起的同时还能让 GitHub 绿点满满,让人不得不佩服。
论文地址:https://www.s3.eurecom.fr/docs/ccs22_fioraldi.pdf
项目地址:https://github.com/AFLplusplus/LibAFL
Artifacts 地址:https://github.com/AFLplusplus/libafl_paper_artifacts
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。