ISSTA 2022 学生志愿者云参会小记

文章目录
ISSTA (The International Symposium on Software Testing and Analysis) 是软件测试与分析方面最著名的国际会议之一,也是中国计算机学会推荐的A类国际学术会议(CCF-A)。由于疫情原因,原本计划在韩国大田市举办的 ISSTA 2022 在 7 月 18 至 22 日以线上形式开展,我有幸作为学生志愿者(student volunteer, SV)在线上参与了会议。

会议由许多主题 session 组成,每个 session 会展示几篇论文,需要一到两名 SV 负责主持 Zoom 会议,依次介绍论文并播放作者提前录好的 15 分钟视频,视频放完后留几分钟时间进行 Q&A,让在场的论文作者回答观众的提问。
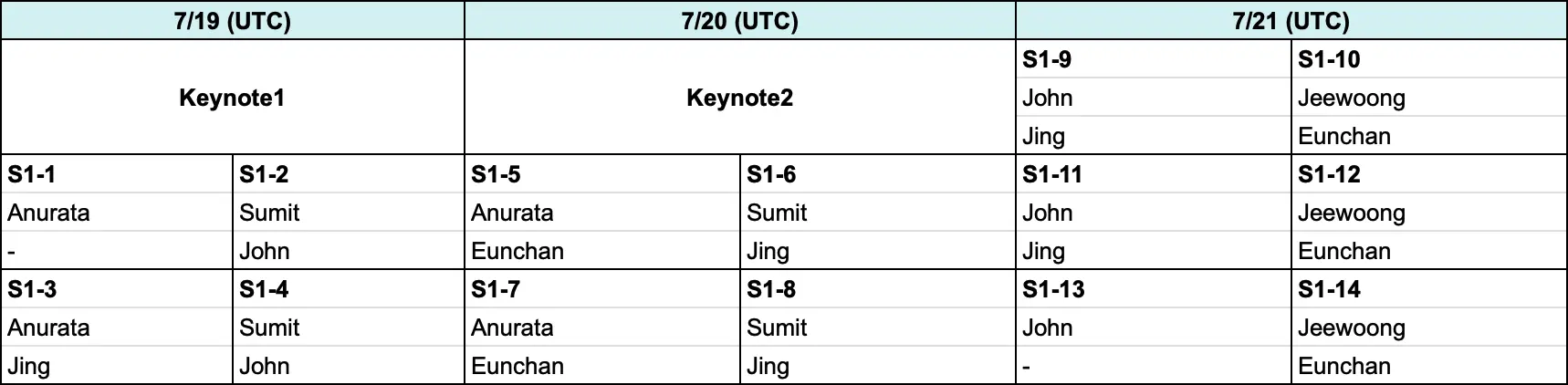
本文会以时间顺序记录三天的 SV 经历,并对所展示的论文做出业余的介绍,如有错误还请多多包涵指正。
Day1
感觉这一场中讨论的问题比较抽象,很多论文我之前连标题关键词都闻所未闻,连研究对象都没搞清楚的话整篇论文就不知所云了。
00:20 - 01:40 Session 1-1: Oracles, Models, and Measurement D
这一段虽然无需做 SV,但为了熟悉节奏还是全程参与了。
Combining Solution Reuse and Bound Tightening for Efficient Analysis of Evolving Systems
Clay Stevens University of Nebraska-Lincoln, Hamid Bagheri University of Nebraska-Lincoln
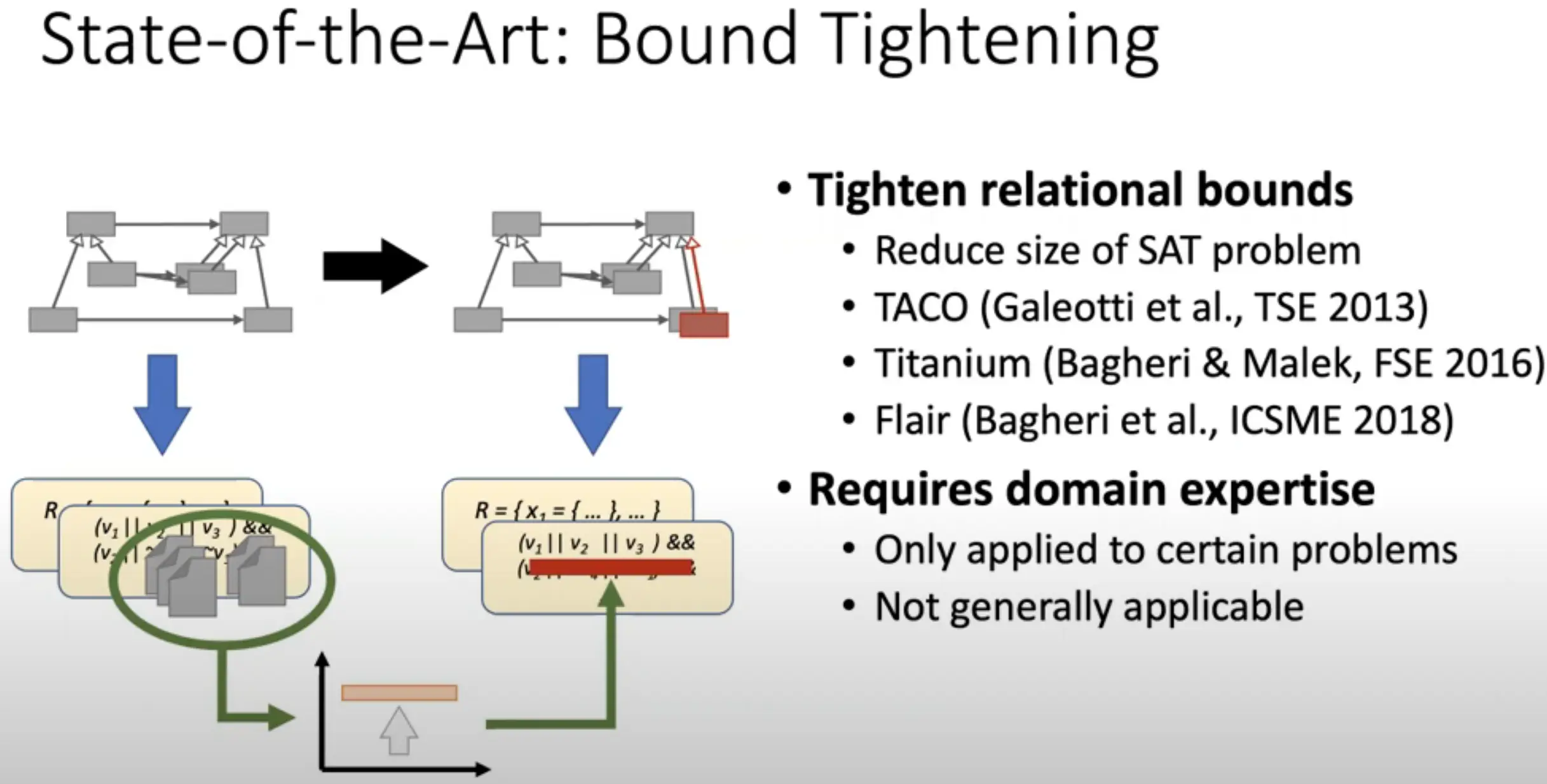
这篇文章被评为了 ACM SIGSOFT distingushed paper,应该是程序形式化验证方面的工作,可惜文中关键的概念如 relational bound, bound tightening 和 solution reuse 我都从未接触过,无法理解本文具体内容。
Evolution-Aware Detection of Order-Dependent Flaky Tests
Chengpeng Li University of Texas at Austin, August Shi University of Texas at Austin
Flaky test 是指软件测试中结果不可靠的测试,其结果时而 pass,时而 fail,本文第二作者 Prof. August Shi 在 UIUC 读博时的导师 Darko Marinov 似乎就在这方面颇有研究。本文重点关注由测试顺序不同导致的 order-dependent flaky test,这是最常见的三种 flaky test 之一,其原因是一些测试(polluter)会污染程序中的 shared state(比如测试类中的 static 变量),从而影响依赖这些状态的测试(victim),polluter 和 victim 的引入和最后的修复在时间上可能间隔很久。作者提到先前的工作 iDFlakies(查了下就是 August Shi 在 UIUC 读博期间发表)可以对一份代码用随机的顺序运行测试来检测 order-dependent flaky test,但因为无法预知何时产生 flaky test,在每次变动时都要运行检测,开销会很大,实际开发中经常运用 Regression Test Selection (RTS) 技术,分析代码的变化及其与测试间的依赖关系,只运行测试的对应一部分子集以减小开销。
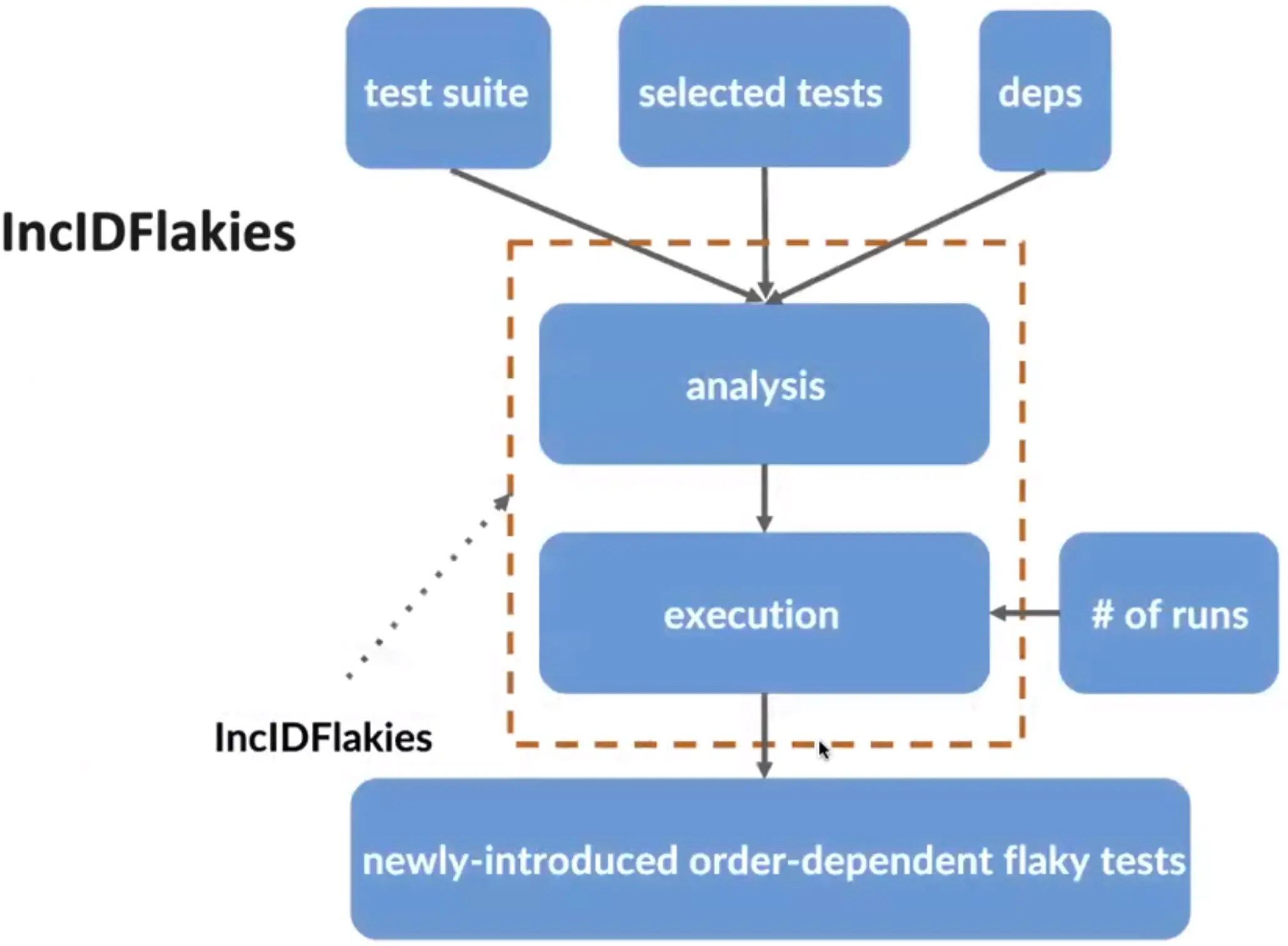
基于 RTS 技术,本文提出了 InclDFlakies 以更高效地检测新引入的 flaky tests,通过对代码类和测试类进行分析可以执行更少的测试,只要分析时间+运行更少测试的时间比 baseline iDFlakies 更短就是成功,实验结果确实如此。
jTrans: Jump-Aware Transformer for Binary Code Similarity Detection
Hao Wang Tsinghua University, Wenjie Qu Huazhong University of Science and Technology, Gilad Katz Ben-Gurion University of the Negev, Wenyu Zhu Tsinghua University, Zeyu Gao University of Science and Technology of China, Han Qiu Tsinghua University, Jianwei Zhuge Tsinghua University, Chao Zhang Tsinghua University
看标题大概知道是用 transformer 做二进制代码相似性检测,内容没有细看。
On the Use of Evaluation Measures for Defect Prediction Studies
Rebecca Moussa University College London, Federica Sarro University College London
UCL 这位姐姐做的幻灯片真是我见过最精美的,图片、动效和字体有种手绘风,不过这样呈现的信息密度较低,而且光看幻灯片很难感知到整体和单页内容的结构,演讲者需要确保自己表达流畅层层引入,观众也要专注听讲才能跟上。与之对立的常见风格是把干货内容文字放在幻灯片中,演讲时照着念,这样就算口语不佳,在表意上也不会有大问题。
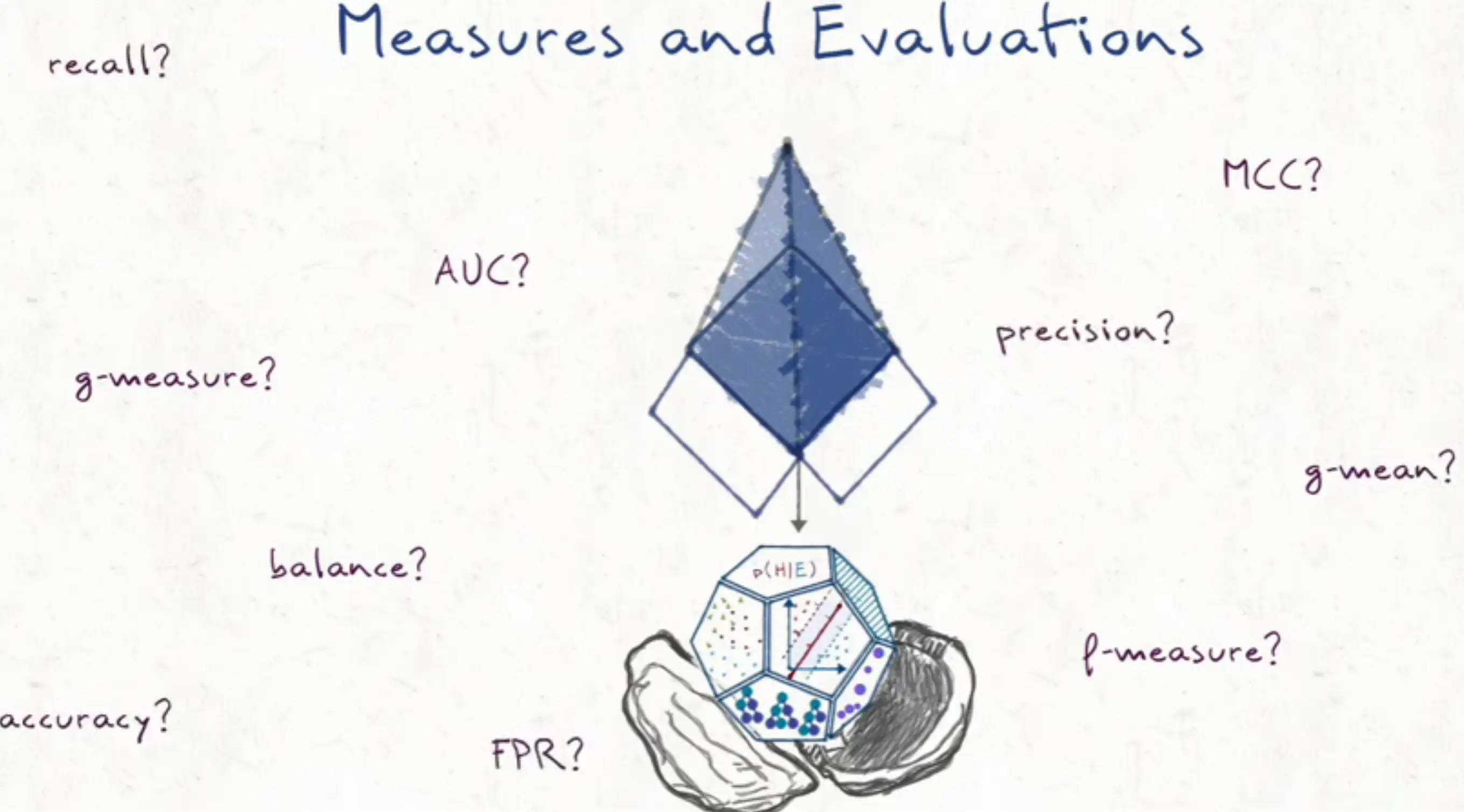
参会当时光被其形式所震撼,没看懂具体内容,会后复盘了一下,其实就是对所有 defect prediction 工作中用到的 evaluation measures 进行调研,是对评价指标的评价。具体来说就是统计历年来 defect prediction 这一工作中用到的指标,比如 AUC, p-measure, recall, precision 等等,这些看起来只是统计学中的不同度量方法,但背后其实反映了在对研究进行评价时的多样性。正如作者在第一张幻灯片中所做的比喻,同一个方块从不同的 viewpoints 和 angles 上观察,既可能是 square 也可能是 diamond。不过对于 defect prediction 这一关键概念,作者只用一两页带过,之后都是在对不同 evaluation measures 被用到的次数做排序和分析,似乎把 defection prediction 换成其他任何研究问题都毫无违和感。总之结论就是,evaluation measures 的选择是在做研究时必须关注的大问题,现在的研究在评价指标选取上没有原理可依,只能部分地反映模型性能,会造成 data imbalance。
02:00 - 03:00 Session 1-3: Oracles, Models, and Measurement A
这一段三篇论文和印度博士姐姐 Anurata Prabha Hridi 分担,第二个视频放完之后由我主持,有些紧张一度担心自己视频没放出声音,结束后立马得到对方的肯定。
Using Pre-trained Language Models to Resolve Textual and Semantic Merge Conflicts (Experience Paper)
Jialu Zhang Yale University, Todd Mytkowicz Microsoft Research, Mike Kaufman Microsoft Corporation, Ruzica Piskac Yale University, Shuvendu K. Lahiri Microsoft Research
合并冲突(merge conflicts)是一个经常发生却容易被忽视的问题,每一个小小的合并冲突就可能拖慢几小时到数天的开发进度,以 Edge 浏览器为例,三个月内就可以产生超过 800 个 commits 仅仅用来解决合并冲突,平均每个冲突就需要花费一个专家半小时来解决,浪费大量人力。用预训练的模型来自动处理可以节省成本,并且可扩展性更强。
Metamorphic Relations via Relaxations: An Approach to Obtain Oracles for Action-Policy Testing
Hasan Ferit Eniser MPI-SWS, Timo P. Gros Saarland University, Germany, Valentin Wüstholz ConsenSys, Jörg Hoffmann Saarland University and DFKI, Germany, Maria Christakis MPI-SWS
之前都没听说过 metamorphic relation 是什么,整体看上去是理论性较强的工作,relaxation 这个概念是获得 oracle 的关键,幻灯片中阐释的比较清楚。

作者还举了具体案例比如公路超车,登陆月球等,实现并开源了 pi-fuzz 框架,针对以上案例对 Metamorphic Oracle (MMOracle) 的效果进行了评估。
Q&A 环节没人提问,为防冷场我问了个愚蠢的问题:发现了哪些 real-world vulnerabilities?作者回答说是在模拟器上实验的,可能这个领域就是如此吧。
An Extensive Study on Pre-trained Models for Program Understanding and Generation
Zhengran Zeng Southern University of Science and Technology, Hanzhuo Tan Southern University of Science and Technology, The Hong Kong Polytechnic University, Haotian Zhang , Jing Li, Hanzhuo Tan Southern University of Science and Technology, The Hong Kong Polytechnic University, Haotian Zhang The Hong Kong Polytech University, Jing Li The Hong Kong Polytech University, Yuqun Zhang Southern University of Science and Technology, Lingming Zhang University of Illinois at Urbana-Champaign
UIUC 张令明老师组里的工作,评估了当前的预训练模型在程序理解和生成(Program Understanding and Generation, PUG)上的效果和鲁棒性,还发现了这些预训练模型都易受对抗样本的攻击,最后给出了一些 practical guidelines。这个问题还是比较新颖且具有现实意义的,像 GitHub Copilot 就是基于大规模预训练模型的产品,或许就有被攻击的风险。

Day2
前一天熬夜导致今天精力不足,基本是印度老哥 Sumit 带飞,我在下面鼓掌。
00:20 - 01:20 Session 1-6: Concurrency, IoT, Embedded A
Binbin Zhao Georgia Institute of Technology, Shouling Ji Zhejiang University, Jiacheng Xu Zhejiang University, Yuan Tian University of Virginia, Qiuyang Wei Zhejiang University, Qinying Wang Zhejiang University, Chenyang Lyu Zhejiang University, Xuhong Zhang Zhejiang University, Changting Lin Binjiang Institute of Zhejiang University, Jingzheng Wu Institute of Software, The Chinese Academy of Sciences, Raheem Beyah Georgia Institute of Technology
佐治亚理工赵彬彬博士和浙大纪守领老师,软件所吴敬征老师等人的工作,大规模分析 IoT 固件中由第三方组件引入的漏洞,没有细看,大致印象是数据图表很多。
Detecting Multi-Sensor Fusion Errors in Advanced Driver-Assistance Systems
Ziyuan Zhong Columbia University, Zhisheng Hu Baidu Security, Shengjian Guo Baidu Security, Xinyang Zhang Baidu Security, Zhenyu Zhong Baidu USA, Baishakhi Ray Columbia University
Understanding Device Integration Bugs in Smart Home System
Tao Wang Institute of Software Chinese Academy of Sciences, Kangkang Zhang Institute of Software Chinese Academy of Sciences, Wei Chen Institute of Software Chinese Academy of Sciences, Wensheng Dou Institute of Software Chinese Academy of Sciences, Jiaxin Zhu Institute of Software Chinese Academy of Sciences, Jun Wei Institute of Software Chinese Academy of Sciences
这两篇论文都是探讨某一物联网场景下的某种特定问题,之前没有了解过。
02:00 - 02:40 Session 1-8: Concurrency, IoT, Embedded D
Deadlock Prediction via Generalized Dependency
Jinpeng Zhou University of Pittsburgh, Hanmei Yang University of Massachusetts Amherst, John Lange Oak Ridge National Lab/University of Pittsburgh, Tongping Liu University of Massachusetts Amherst
Chao Li Beijing Institute of Control Engineering and Beijing Sunwise Information Technology Ltd, Rui Chen Beijing Institute of Control Engineering and Beijing Sunwise Information Technology Ltd, Boxiang Wang Xidian University and Beijing Sunwise Information Technology Ltd, Tingting Yu Beijing Institute of Control Engineering and Beijing Sunwise Information Technology Ltd, Dongdong Gao Beijing Institute of Control Engineering and Beijing Sunwise Information Technology Ltd, Mengfei Yang China Academy of Space Technology
这两篇论文都是探讨如何检测程序中一些的并发问题,比如死锁和原子性违反,没有细看。
Day3
期待已久的 fuzzing 专场,不过 SV 工作有点小意外,原本该主持 Zoom 会议的 John 持续失联,因此两个 Session 全部由我独自主持,还好 Sonal Mahajan 和 Donghwan Shin 两位 SV Co-Chair 一直在鼓励我并在台下随时提供支持。感觉今天会议气氛有点冷,每篇论文都没有人开麦提问,都是我自己提问来试图暖场。
23:00 - 00:00 Session 1-9: Fuzzing and Friends A
Almost Correct Invariants: Synthesizing Inductive Invariants by Fuzzing Proofs
Sumit Lahiri Indian Institute Of Technology Kanpur, Subhajit Roy IIT Kanpur
本文作者 Sumit Lahiri 就是昨天和我一场的 SV,这篇论文讲的是用 fuzzing 来生成 inductive invariants,我们知道可以用霍尔三元组来进行程序验证,但对于包含循环的程序,需要归纳出 loop invariants(循环不变式,算法导论开篇就讲过这个概念) 来构建正确性证明。
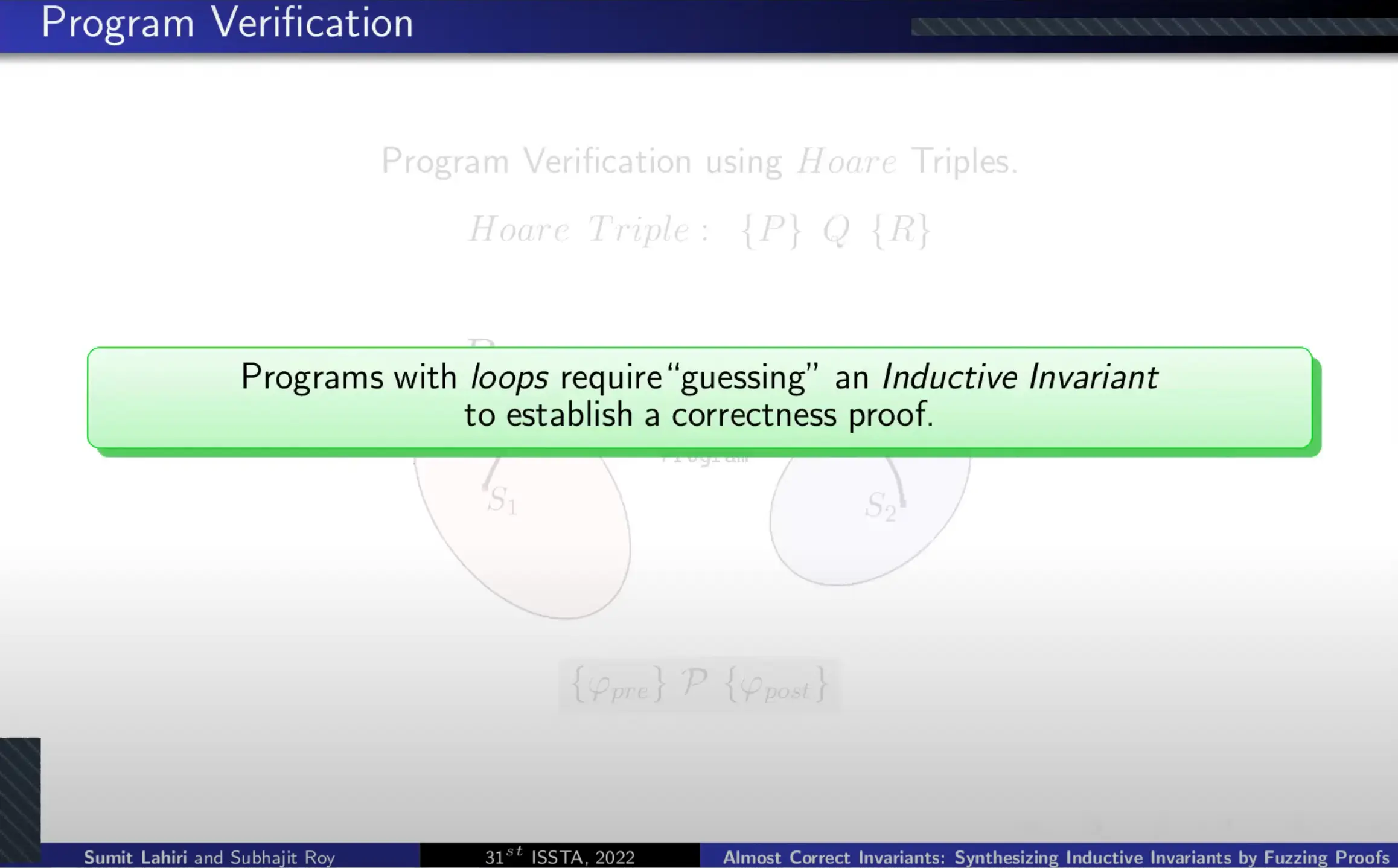
现有的工作比如 Code2Inv 对程序进行逻辑编码并使用定理证明器来合成 inductive loop invariants,但问题是程序中可能包含 opaque operations,无法获得其形式语义,比如外部函数和系统调用等,这时基于逻辑编码的现有工作就失效了。而本文就使用 proof fuzzing 来检查生成 inductive loop invariants 的正确性,开发了工具 ACHAR,通过设置 Reach Oracle 来判断 invariant 是否合法。最终实验结果在性能上确实稍好于 Code2Inv。
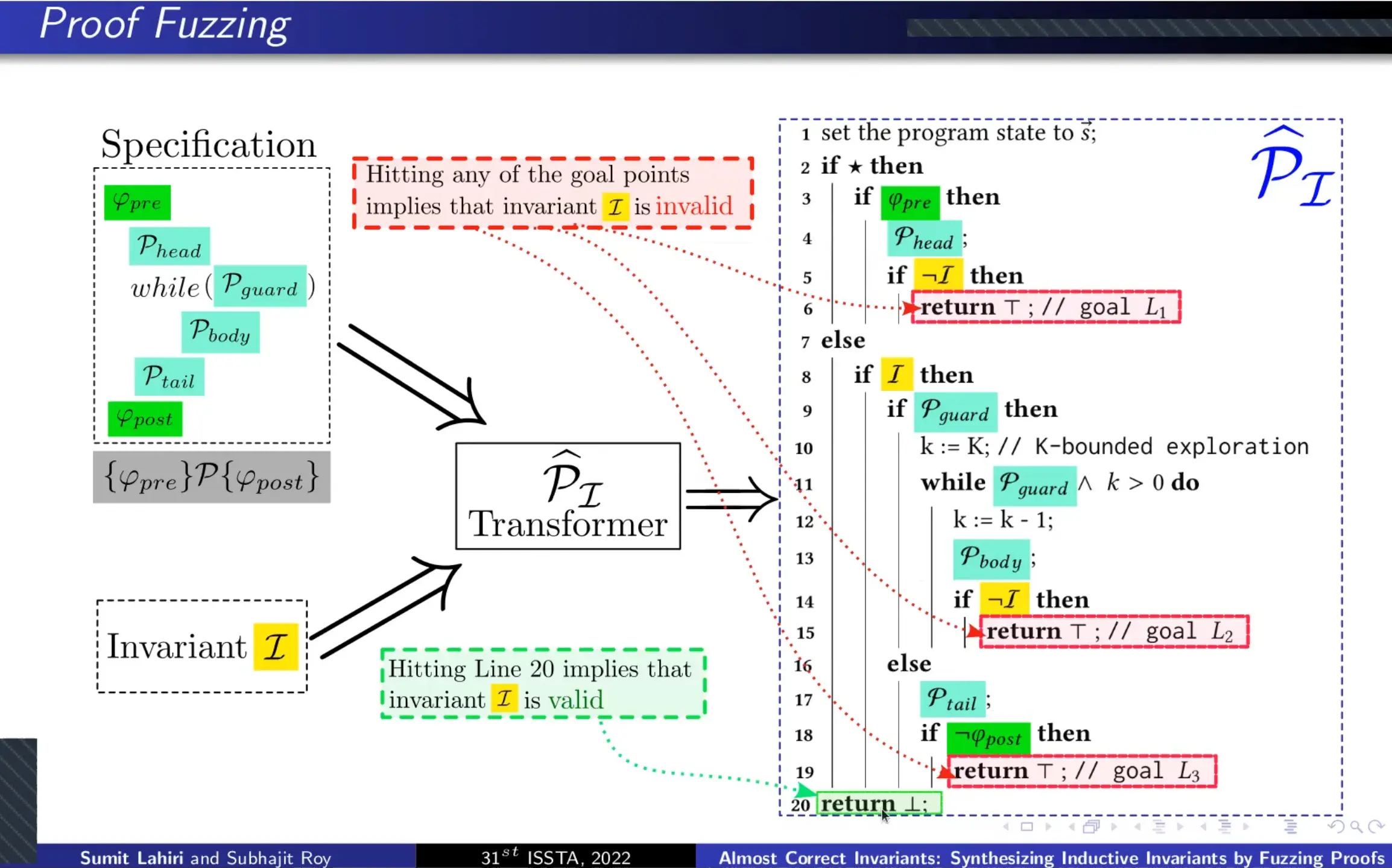
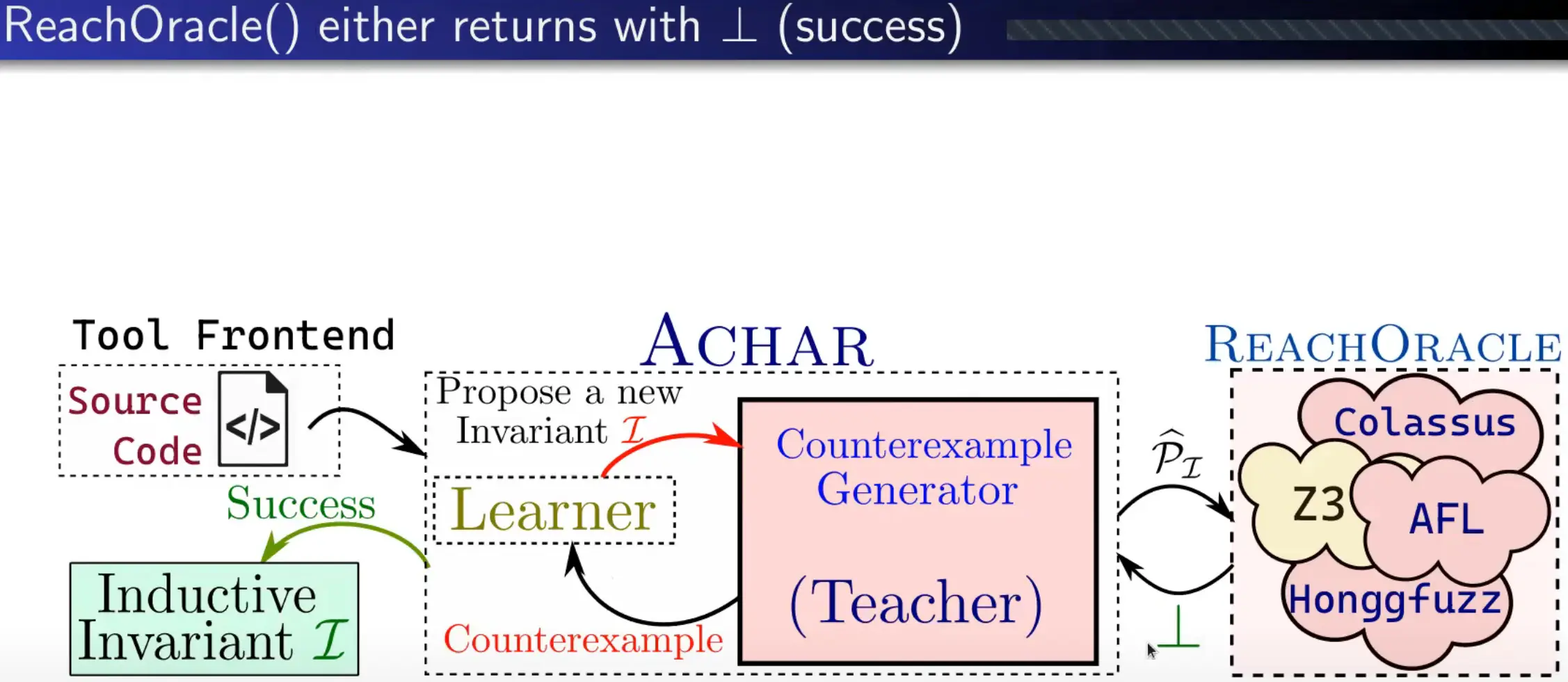
因为从 ACHAR 的结构图中看到可以用 AFL 作为后端,我提问该如何理解 proof fuzzing 中的覆盖导向,Sumit 的回答语速较快没太听清,似乎是说没覆盖导向应该也可以。
另外 ACHAR 在梵语中是 immovable 和 invariant 的意思,在其他工作几乎清一色命名为 XXXFuzz 很容易撞车的今天,这名字显得很有文化。
MDPFuzz: Testing Models Solving Markov Decision Processes
Qi Pang HKUST, Yuanyuan Yuan HKUST, Shuai Wang HKUST
港科大王帅老师组里的工作,听完后大概只知道是用强化学习的 reward 作为 fuzz 的反馈,Q&A 环节问了下 initial seed 是怎么选的,对 fuzz 效果有何影响,作者回答说初始环境是随机分布,选取的时候要避免在开始就 crash 掉。
SnapFuzz: High-Throughput Fuzzing of Network Applications
Anastasios Andronidis Imperial College London, Cristian Cadar Imperial College London
这篇文章比较接近传统意义上的 fuzz 所以还算比较好理解,早在 5 月知乎上就有对这篇 SnapFuzz 的解读,可能是因为其在性能上十几倍的提升实在亮眼,毕竟天下武功唯快不破。作者 Anastasios Andronidis 的展示非常清晰,从 fuzz 的基本概念讲起,提到网络 fuzz 的痛点是通信协议的 awareness 和 statefulness,需要对副作用进行隔离和重置,又介绍了 SOTA 工作如 AFL Net,其仍然需要大量人力用于配置网络参数和重置状态,性能也较差。
作者举了 dcmqrscp 这个例子,fuzzer 需要被配置在初始化和接发网络包的时候进行等待,每次文件读写操作也需要维持文件系统的状态。

为了提升 fuzzer 性能,作者使出了浑身解数,下图展示了 SnapFuzz 的关键组成部分

Q&A 环节我先提问 SnapFuzz 运用二进制重写等技术是否会导致一些兼容性问题,老哥打开摄像头爽快回答 “That’s a really good question”,估计他早已料到会有这种问题,在论文的 limitations 这节里已经阐述了一些特殊场景下可能的问题,大部分情况下还是正常工作的。看时间还够我又问了下是否支持对二进制的 fuzz 和是否能基于 QEMU 对 IoT 固件中的网络服务进行 fuzz,老哥也耐心回答说因为基于 AFLNet 开发的,可以通过源码插桩获得更多覆盖率信息,直接对二进制 fuzz 应该也可以,但没有测试过到底能否在 QEMU 上做 fuzz。
00:40 - 01:20 Session 1-11: Fuzzing and Friends D
Yaowen Zheng Nanyang Technological University; Beijing Key Laboratory of IOT Information Security Technology, Institute of Information Engineering, CAS, China;, Yuekang Li Nanyang Technological University, Cen Zhang Nanyang Technological University, Hongsong Zhu Beijing Key Laboratory of IOT Information Security Technology, Institute of Information Engineering, CAS, China; School of Cyber Security, University of Chinese Academy of Sciences, China, Yang Liu Nanyang Technological University, Limin Sun Beijing Key Laboratory of IOT Information Security Technology, Institute of Information Engineering, CAS, China; School of Cyber Security, University of Chinese Academy of Sciences, China
对基于 Linux 的 IoT 程序进行灰盒 Fuzz,一般都是使用 QEMU 模拟,分为 user-mode 和 full-system 两种模式:前者直接将系统调用转发给宿主机,性能更好但兼容性差;后者模拟了整个系统兼容性好,可性能太差故不常用于实践。之前的 SOTA 工作是采用混合模拟的 FIRM-AFL,在 user-mode 执行常规代码,系统调用则转发给 full-system emulation,但当 program under test (PUT) 频繁发起系统调用时,性能仍然受到影响。
本文提出了 EQUAFL,关键思路是设置执行环境以让 PUT 的系统调用能直接传给宿主机,这样 PUT 仍在 user-mode 执行,避免 full system emulation 的开销。主要分两步,先在 full system emulation 下执行并观察一些能设置程序执行正常环境的关键行为,比如启动变量的设置,配置文件的动态生成和 NVRAM 配置等,之后在 user-mode 重放这些行为并进行 fuzz。

观察记录不同的行为也需要相应的手段,以启动变量的设置为例,argv 和 env 可能存在各种地方,不过我们知道每当新进程启动,内核都会调用 do_execve 函数,通过分析 Linux 内核源码可以找到哪些地方能 dump 出 argv 和 env 的值。

会议时没太理解技术细节,感觉理论上确实做到了兼容和性能的统一,实验结果也是远远超过 SOTA,于是 Q&A 环节我就问这个工作 workload 怎样,observation 和 replay 都能自动化进行还是需要人工。作者回答说实验的时候只是针对了几个特定的设备,对于每种设备来说自动化程度应该还是挺高的。
TensileFuzz: Facilitating Seed Input Generation in Fuzzing via String Constraint Solving
Xuwei Liu Purdue University, Wei You Renmin University of China, Zhuo Zhang Purdue University, Xiangyu Zhang Purdue University
普渡大学张翔宇老师组里的工作,fuzz 中 seed 的生成算是个老大难问题,直接影响代码覆盖率,作者提到现有的工作主要是符号执行和基于梯度的搜索以及 hybrid fuzzing,但在这些技术在某种场合也无法奏效。作者以 ZIP 格式为例,说明了 hybrid fuzzer 无法执行过全部的检查,而 string solver 更适合求解这些约束。
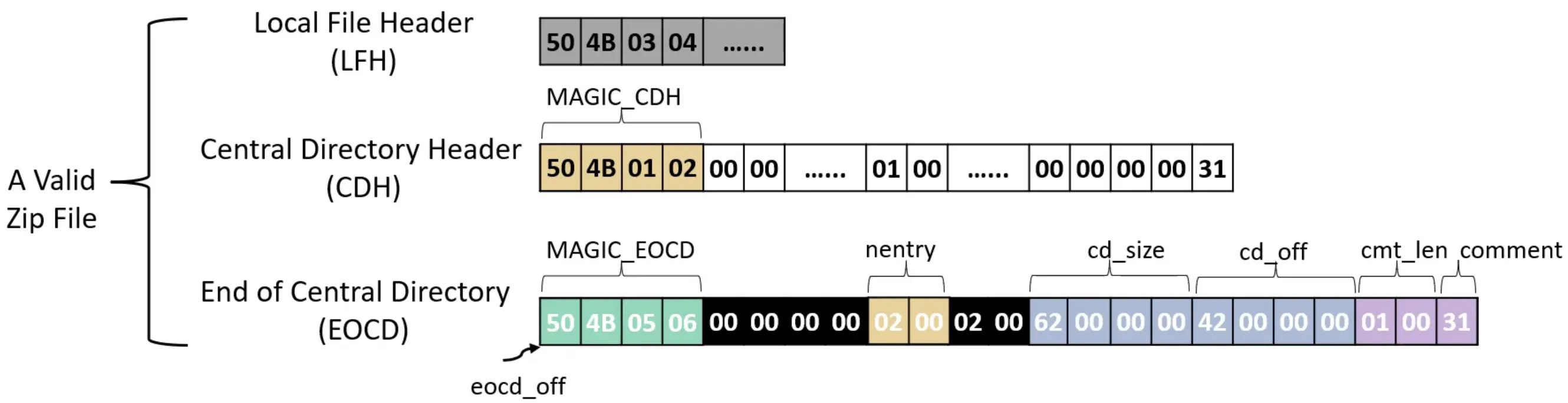

整体 workflow 如下图所示,后面看了论文里的图比这张还更复杂。
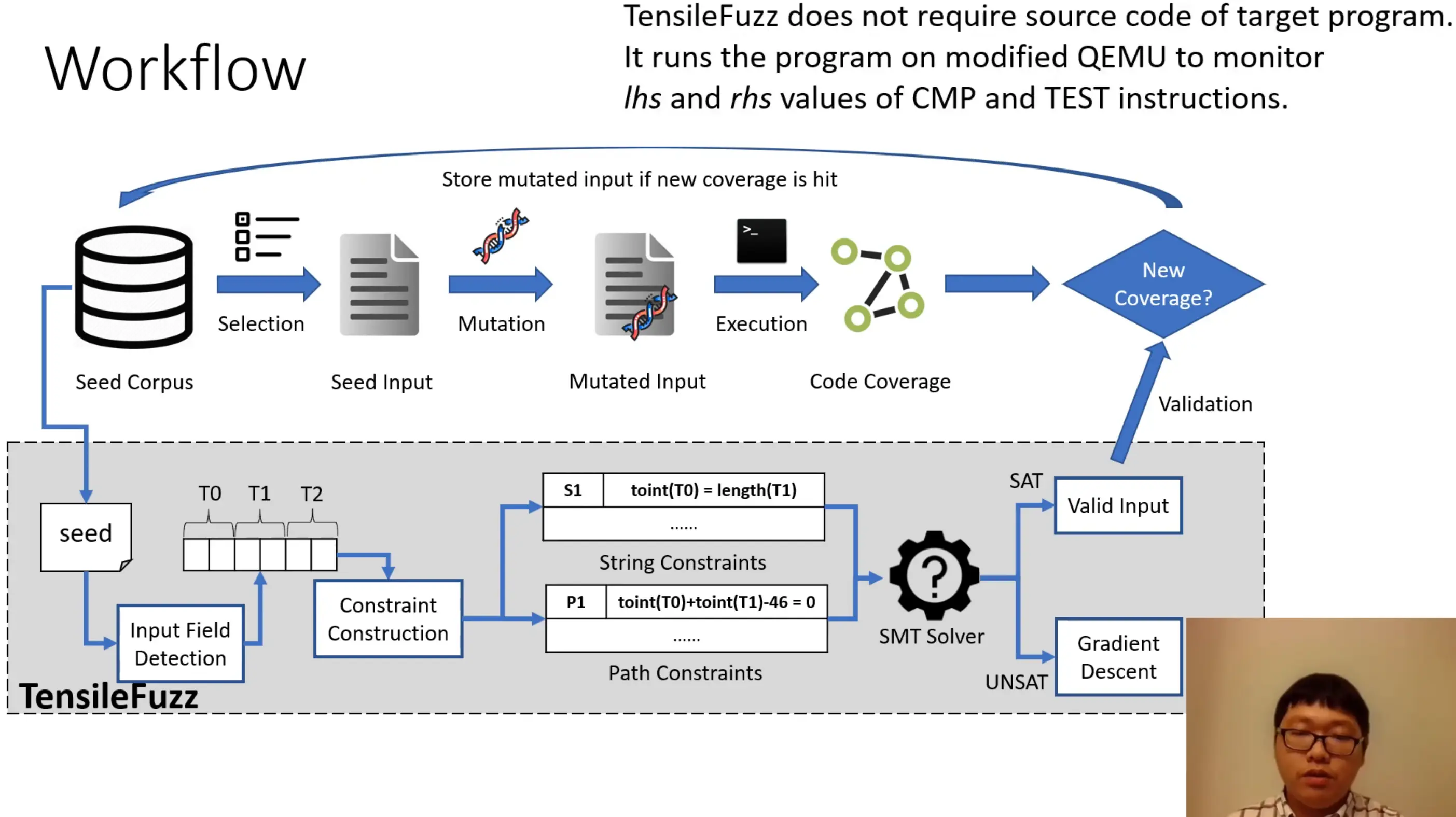
会议时我没有太明白 input field detection 是怎么做的,因为作者举例是用 ZIP 这种明确的格式,就提问是否用到 dictionary 来表示文件结构,作者回答 “This is a good question. But actually not.” 最后我理解下来 fields 应该就是把输入当成字符串,通过 SMT Solver 来求解的,并不需要在开始给出结构,要弄懂原理可以看论文中的公式推导。
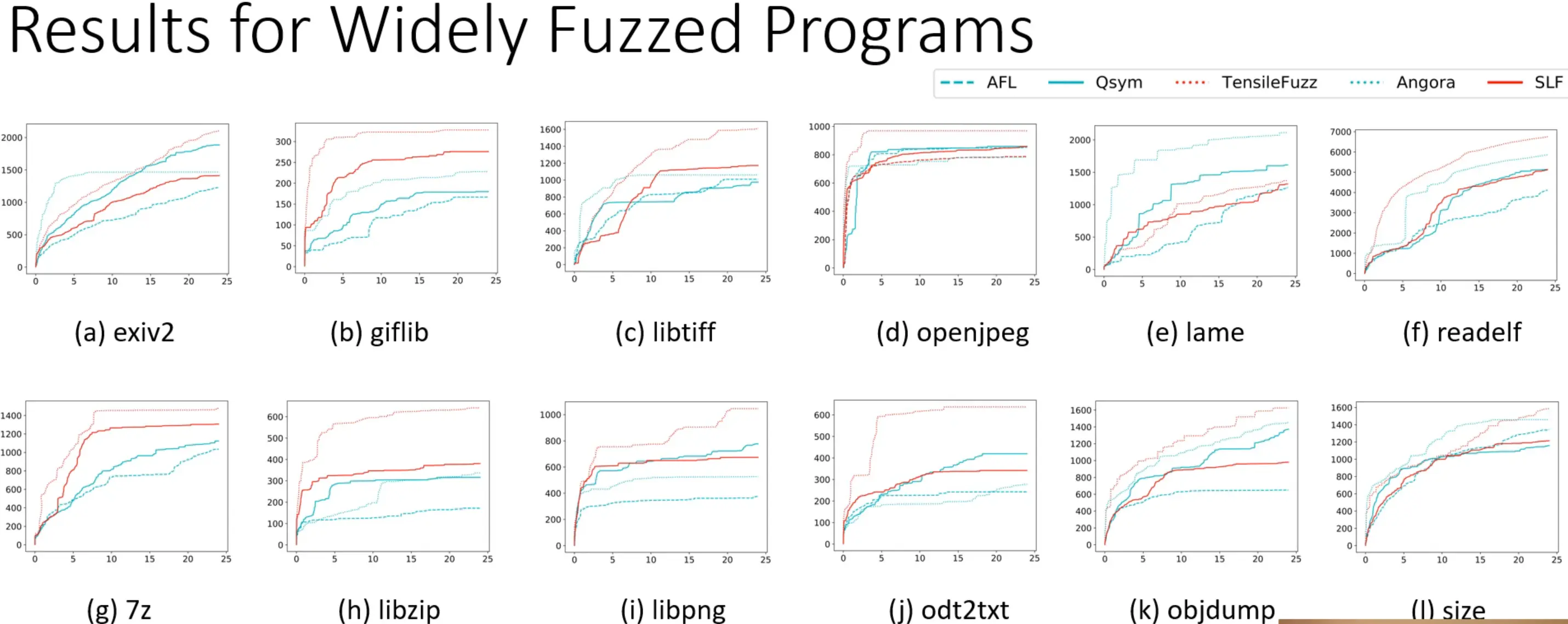
实验结果如上图,TensileFuzz 在除了 lame 之外的所有程序上表现更优,因为 lame 这个 MP3 编码器中有很多算术关系,Angora 这种基于梯度的 fuzzer 会更加高效。
总结
作为学生志愿者没有物质上的回报,却要付出 10h+ 的时间,因为时差要连续三天熬夜导致身心俱疲。
但为了理解会议内容,增进和作者的互动,我也走马观花看了一些论文,接触了之前完全不了解的方向。
与此同时,我也算第一次参与了学术会议的组织,与会者观看直播时的岁月静好,其实背后都是志愿者的负重前行。
感谢 Sonal Mahajan 和 Donghwan Shin 两位 SV Co-Chair 以及其他 SV 对我的鼓励和支持,尽管我们素未相识,却能互相信任,一起努力保障线上会议的正常开展,这本身就是一件很有意思的事。我也曾在开源世界感受过这种弱连接的神奇,故而非常珍惜和世界各地的研究者交流的机会,或许也正是因为之前的开源经历,我才能以本科生的身份入选为志愿者,希望之后的自己能一直保持这种开放的心态,这可能和代码工作本身的开源同样重要。
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。